
Storage. Backup. Virtualisierung.
Storage Tiering V1.10 (c) Stor IT Back 2026
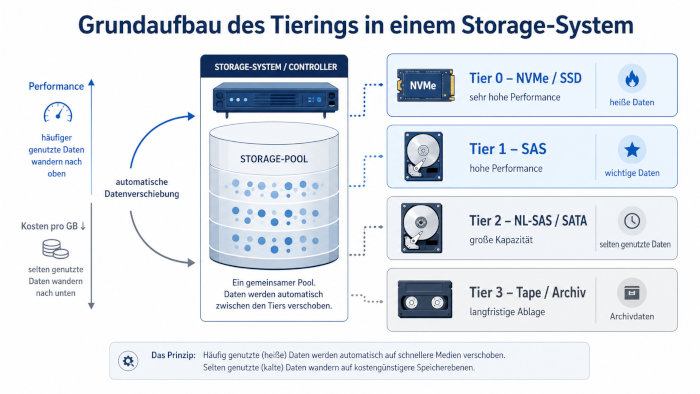
Der Begriff Tiering kommt aus dem Englischen und bedeutet so viel wie Abstufen oder Staffelung. Die Abstufung besteht bei Durchsatz und Antwortzeit der Medien, also im Allgemeinen der Performance. Bei Speichermedien gibt es aber nicht nur Performance-Unterschiede sondern auch extreme Preisunterschiede. Die SSDs und NVMe sind am schnellsten, leider aber auch am teuersten. Die SAS-Festplatten (heute meist mit 10k) sind am zweitschnellsten, kostengünstiger als SSDs, aber trotzdem noch recht teuer bei großen Kapazitäten. Danach kommen die NL-SAS bzw. SATA-Festplatten mit 7.200 Umdr./min und dann Tape als Auslagerung.
Es wäre also die preislich günstigste Lösung bei bester Performance, wenn man die SSD-Platten nur für
hochperformante Daten nutzen würde, die wichtigen und performanten Daten auf SAS-Festplatten speichert und alles andere auf
den NL-SAS oder SATA-Platten ausgelagert.
Und genau das ist der Ansatz von Tiering: Maximale Leistung bei minimalen Kosten.
Tier 0: Für wichtige und performante Daten, z.B. Datenbanken
Tier 1: Für wichtige Daten, aber von der Performance nicht so relevant, z.B. Anwendungen oder selten genutzte Datenbanken
Tier 2: Für selten genutzte Daten oder Daten ohne Performance-Ansprüche z.B. Fileserver oder Archive
Tier 3: Daten die sehr selten genutzt werden, alte Fileserverdaten oder Archive, Auslagerung auf Tapes (eher selten)
Neben der Kostenoptimierung kann also zusätzlich auch Energie
eingespart werden.
Anmerkung zu SSDs:
Sie haben einen großen Nachteil: Auf SSDs kann nicht unendlich häufig
geschrieben werden, einzelne Blöcke fallen bei vielen Schreibzugriffen schneller aus.
Aber beim Tiering ist das kein Problem, eine Optimierung kann zusätzlich auch noch auf
die Zugriffsart erfolgen. Schreibzugriffe gehen zum Beispiel erst immer auf Tier 1 und es erfolgt
dann eine Umlagerung auf Tier 0, wenn häufig gelesen wird.
In die Richtung der Kosteneinsparung bei SSDs geht die
Deduplizierung der Daten, gerade auf SSDs. Zusammen
mit der Komprimierung ein häufig eingesetztes Verfahren, um Kosten zu sparen.
Kurz: Storage Tiering ist das Verschieben von Daten auf verschiedene Typen von Speichermedien nach vordefinierten Regeln.
Historie zu den Tiers:
Als der Begriff Tiering mit den Abstufungen erfunden wurde, gab es noch keine SSDs. Daher wurde als Tier 1 die
damals schnellsten FC- und SCSI-Platten festgelegt. Als dann die schnelleren SSDs auf den Markt kamen, behielten
die anderen Stufen ihre Namen, die SSDs wurden zu Tier 0. Es muss auch nicht jede Tier-Stufe genutzt werden, auch Tier 0 in Verbindung mit Tier 2 ist meist möglich.
Beim File-Tiering (siehe unten) ist die Unterscheidung bzw. die Einordnung sehr einfach, beim Block Tiering
wird es komplizierter. Das File Tiering hat der Fileserver übernommen und
der brauchte nur die Filesystem-Informationen auszuwerten. Beim Block Tiering übernimmt
das Speichersubsystem diese Aufgabe und es kennt weder Filesystem noch Dateien, es
kennt nur Blöcke auf den Festplatten.
Und genauso wie im Filesystem ermittelt die Tiering-Anwendung im Speicher-Controller
die Zugriffshäufigkeit von Blöcken und verschiebt mit diesen Informationen
die Blöcke zwischen den Festplatten-Tiers.
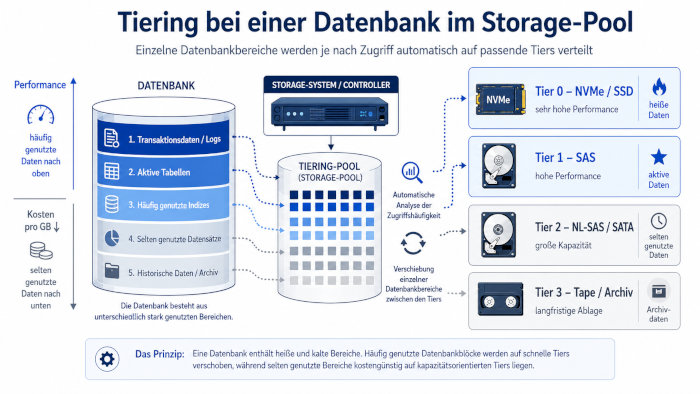
Ein Beispiel einer Datenbank: Die Datenbanken bestehen auf der Festplatte aus
Blöcken, die entweder häufig genutzt werden oder aus Blöcken
die nur selten gelesen werden. Ermittelt der Controller eine kleine Nutzungsfrequenz,
so werden die Blöcke auf SATA-Platten (oder NL-SAS) ausgelagert. Bei häufigen Zugriffen
bleiben sie auf schnellen SAS-Platten oder werden später darauf verschoben.
Ist auch SSD-Speicher oder NVMe vorhanden, so können extrem häufig gelesene
Daten auch auf diese SSDs oder NVMe verschoben werden. Da SSDs aber nicht so häufig
beschrieben werden sollen, werden alle Write-I/Os erst mal auf die SAS-Platten
geschrieben und dann analysiert. Das Migrationsverhalten (Tiering)
ist von außen selten konfigurierbar. Das kann Probleme mit sich bringen.
Welche Vorteile bringt diese Methode des Verschiebens? Für die Performance wichtige Blöcke
sind auf schnellen Platten, schnelle Platten sind aber teurer in der Anschaffung.
Also sollten sie auch nur für hochperformante Daten genutzt werden, alles
andere geht auf NL-SAS-Platten und spart teuren Speicherplatz. Auch SSDs lassen
sich ideal einsetzen. Wenig Speicherplatz für extrem performante Daten
und wenig Schreibzugriffe auf die SSDs. Ideale Bedingungen
für die SSDs, der Speicherplatz wird passend genutzt und die Schreibzugriffe
werden reduziert.
Beim Block Tiering ist allerdings keine manuelle Verschiebung der Blöcke
möglich, dies muss eine Anwendung im Speicher-Controller vollständig
erledigen. Probleme können auftreten, wenn der Anwender mit der Verteilung
nicht einverstanden ist. Wird zum Beispiel eine Datenbank auf den nächtlichen
Batchbetrieb automatisch optimiert, kann es sein, dass beim Online-Betrieb am
Tag das Tiering nicht ideal ist. In vielen Fällen lassen sich solche
Schwankungen durch eine passende Konfiguration verhindern.
Beim File Tiering, also dem dateibasierten Verschieben,
wird immer die ganze Datei betrachtet. Zum Beispiel in einem Fileserver: Es
gibt Dateien, die häufig genutzt werden, Dateien die selten genutzt werden
und viele Daten die eigentlich nur einmal geschrieben werden, aber danach nie
wieder genutzt werden. Da kann die Aufteilung auf die einzelnen Storage-Tiers
sehr einfach erfolgen. Es muss nur die Änderungs- und Zugriffshäufigkeit
der Datei ermittelt werden und dann eine Verschiebung auf die unterschiedlichen
Plattengruppen vorgenommen werden.
Dies wird schon sehr lange unter dem Begriff
HSM (Hierarchisches Speicher-Management)
eingesetzt. Die HSM-Funktion nutzt also das Tiering.
Ein manuelles File-Tiering ist auch möglich. Auf einem Fileserver muss
nur nach alten und nicht genutzten Dateien gesucht werden und diese können
dann verschoben werden. Dann tritt allerdings das Problem auf, dass keiner diese
Daten später wieder finden kann. Also braucht man doch eine HSM-Software,
die den Zugriff über die einzelnen Tiers ermöglicht.
Als Praxis-Beispiel nehmen wir die Dell Unity XT Familie, dieses Feature nennt Dell EMC FAST VP und es ist in den Standard-Features
zum Beispiel der Dell Unity XT380 enthalten. Das Tiering kann bei diesem System also kostenfrei genutzt werden. Die einzelnen Tiers
werden bei Dell etwas anders benannt:
Tier 0 wird zu Extreme Performance Tier
Tier 1 wird zu Performance Tier
Tier 2 wird zu Capacity Tier
In den Extreme Performance Tier kommen die Flash-Drives, also im Falle der Unity sind das SSDs. Im Performance Tier entweder 10k oder 15k SAS Platten,
also drehende HDDs. Im Capacity Tier dann die NL-SAS Platten. Also eine Aufteilung ganz nach dem Standard.
Diese einzelnen Tiers werden über einen RAID-Level in einen Pool zusammengefasst. Das ist also das Wichtige an diesem Konzept, die unterschiedlichen Platten mit
unterschiedlichen RAID-Leveln sind im gleichen Pool. Hört sich im ersten Moment recht seltsam an, aber die Daten müssen ja die Möglichkeit haben, auf allen 3 Tiers landen zu
können.
Dell hat für die Unity eine feste Slice-Größe für das Tiering von 256 MB. Damit werden immer diese 256 MB großen Blöcke für das Tiering, also das Verschieben der Daten
betrachtet und später auch verschoben. Aber warum so große Blöcke, da ist ja kaum eine Unterscheidung möglich. Na ja, je kleiner die Blöcke sind, desto größer ist der Aufwand
für die Ermittlung der Zugriffe. Und diese Größe scheint ein guter Mittelwert zu sein, ähnliche Größen werden auch von anderen Herstellern genutzt.
Für den Pool kann jetzt nur noch die Zeit vorgegeben werden, in der die Daten optimiert, also verschoben werden. Eine Start-Zeit und eine Laufzeit. Dies sollte man so wählen, dass es
nicht in die Hauptlastzeit fällt. Mehr ist da nicht vorzugeben.
Alles Weitere erfolgt beim Anlegen der LUN und kann für jede LUN individuell vorgegeben werden. Ich kann also auf diesem Tiering Pool auch eine LUN anlegen, für die das Tiering nicht
aktiv ist, sondern die fest auf einem Tier liegt. Damit lässt sich das Tiering sehr individuell einstellen. Für eine Standard-LUN kann man einen Start-Tier vorgeben. Auf diesem Tier
werden neue Daten als erstes abgelegt. Hier kann man zum Beispiel die SSDs schonen und die Neuablage auf dem Tier 1 durchführen und erst später optimieren. Oder wenn die
Performance sehr wichtig ist, gleich auf Tier 0 und dann optimieren.
Aber auch eine LUN ohne Tiering kann angelegt werden. Zum Beispiel für ein Test-System, da brauche ich weder Tier 0 noch Tier 1, die Tests sollen nur auf Tier 2 erfolgen. Also legt man
die LUN fest auf Tier 2 an. Ein automatisches Tiering ist dann für diese LUN deaktiviert. Oder eine LUN für eine sehr wichtige Datenbank, die kann dann fest auf Tier 0 gelegt werden.
Auch dort ist dann kein Tiering aktiv, die Daten bleiben immer auf LUN 0.
In der Praxis ist es meist sinnvoll immer das Tiering zu nutzen, weil jede Datenbank und jede Applikation haben Bereiche mit wenigen Zugriffen. Und damit kann Speicherplatz auf
dem teuren Tier 0, den SSDs, gespart werden für noch mehr Daten, die Performance brauchen.
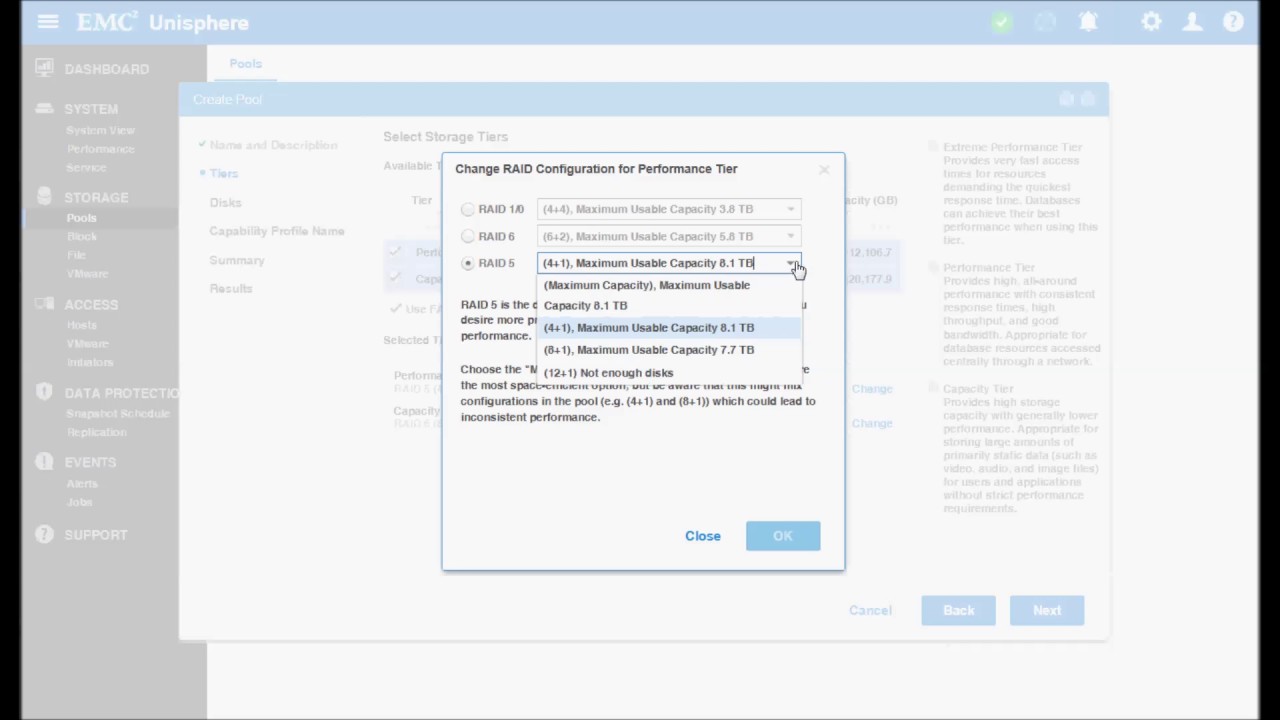
Tiering mit dem FAST VP Feature der Dell Unity XT Serie
Was bedeutet Tiering in einem Storage-System?
Tiering bezeichnet die automatische oder regelbasierte Verteilung von Daten auf unterschiedliche Speicherklassen. Häufig genutzte Daten werden auf schnelle Speichermedien wie NVMe oder SSD verschoben, während selten genutzte Daten auf kostengünstigere Medien wie NL-SAS, SATA oder Archivspeicher wandern. Ziel ist es, hohe Performance dort bereitzustellen, wo sie wirklich benötigt wird. Gleichzeitig werden Kosten gesenkt, weil nicht alle Daten dauerhaft auf teurem Hochleistungsspeicher liegen müssen.
Warum ist Tiering im Rechenzentrum sinnvoll?
In Rechenzentren wachsen Datenmengen oft schneller als Budgets und verfügbare Stellfläche. Tiering hilft dabei, vorhandene Speicherressourcen effizienter zu nutzen, weil heiße Daten auf schnelle Medien und kalte Daten auf kapazitätsstarke Medien verteilt werden. Administratoren profitieren von besserer Auslastung und weniger manuellem Aufwand. Entscheider erhalten eine technische Möglichkeit, Performance und Kosten besser in Einklang zu bringen.
Welche Speicherklassen werden typischerweise für Tiering eingesetzt?
Typische Tiers sind NVMe oder SSD für sehr hohe Performance, SAS-Festplatten für wichtige produktive Daten, NL-SAS oder SATA für große Kapazitäten und Tape oder Archivspeicher für langfristige Ablage. Die genaue Einteilung hängt vom Storage-System und vom Hersteller ab. In vielen Systemen werden drei Ebenen verwendet, zum Beispiel Performance Tier, Capacity Tier und Archive Tier. Wichtig ist nicht der Name der Ebene, sondern die passende Zuordnung von Datenzugriff, Performancebedarf und Kosten.
Ist Tiering abhängig vom verwendeten Protokoll wie FC, iSCSI, NFS oder SMB?
In vielen Storage-Systemen arbeitet Tiering unterhalb der Protokollebene. Das bedeutet: Ob ein Server per Fibre Channel, iSCSI, NFS oder SMB zugreift, ist für das interne Tiering oft nicht entscheidend. Das Storage-System analysiert intern, welche Blöcke oder Dateien häufig genutzt werden, und verschiebt diese auf passende Speicherklassen. Für die Planung ist aber wichtig, welche Workloads über welches Protokoll angebunden sind, weil Block- und File-Zugriffe unterschiedlich bewertet und optimiert werden können.
Welche Rolle spielt Tiering bei Datenbanken?
Datenbanken bestehen aus vielen unterschiedlichen Bereichen, zum Beispiel Transaktionslogs, aktiven Tabellen, Indizes, historischen Datensätzen und Archivdaten. Nicht alle Bereiche werden gleich häufig genutzt. Ein gutes Tiering-System kann häufig gelesene oder geschriebene Datenbankbereiche auf schnelle Tiers verschieben und selten benötigte Bereiche auf günstigeren Speicher legen. Dadurch kann eine Datenbank von hoher Performance profitieren, ohne vollständig auf teurem NVMe- oder SSD-Speicher liegen zu müssen.
Ist Tiering für virtuelle Maschinen geeignet?
Ja, Tiering kann bei Virtualisierungsumgebungen sehr nützlich sein. Virtuelle Maschinen enthalten oft aktive Bereiche, die ständig genutzt werden, und viele ruhige Datenbereiche, die nur selten gelesen werden. Das Storage-System kann diese unterschiedlichen Zugriffsmuster erkennen und entsprechend verteilen. Besonders sinnvoll ist Tiering bei gemischten Workloads, zum Beispiel wenn produktive Server, Testsysteme und Archivdaten denselben Storage-Pool nutzen.
Welche Workloads profitieren besonders von Tiering?
Besonders profitieren Workloads mit wechselnden Zugriffsmustern. Dazu gehören Datenbanken, ERP-Systeme, E-Mail-Systeme, Fileserver und virtuelle Serverlandschaften. Auch Umgebungen mit Monats- oder Jahresabschlüssen können profitieren, weil Daten zeitweise sehr aktiv und später kaum noch genutzt werden. Ein typisches Beispiel ist ein Fileserver, bei dem aktuelle Projektdaten schnell verfügbar sein müssen, ältere Projektordner aber kostengünstig abgelegt werden können.
Wie erkennt man, ob Tiering richtig funktioniert?
Ein funktionierendes Tiering zeigt sich an stabilen Antwortzeiten und einer sinnvollen Auslastung der einzelnen Speicherklassen. Administratoren sollten prüfen, ob der schnelle Tier nicht dauerhaft überfüllt ist und ob kalte Daten tatsächlich auf günstigere Speicherbereiche verschoben werden. Viele Storage-Systeme bieten dafür Statistiken zur Tier-Auslastung, I/O-Verteilung und Antwortzeit. Wichtig ist, nicht nur die Kapazität zu betrachten, sondern auch Latenz, IOPS und Durchsatz.


