
Stor IT Back - Ihr Speicherspezialist
NFS - Network File System V1.5 (c) Stor IT Back 2026
Für eine Client-Server-Architektur müssen Dateien zwischen verschiedenen Clients und zentralen Servern ausgetauscht werden. Dabei können sowohl Server wie auch Clients unterschiedliche Betriebssysteme und Dateisysteme nutzen. Dafür entwickelte Sun Microsystems (jetzt Oracle) das NFS-Protokoll, anfangs nur für die interne Verwendung zum Datenaustausch in ihrer Unix-/Solaris-Umgebung. Erst die Version 2 wurde für Kunden freigegeben.
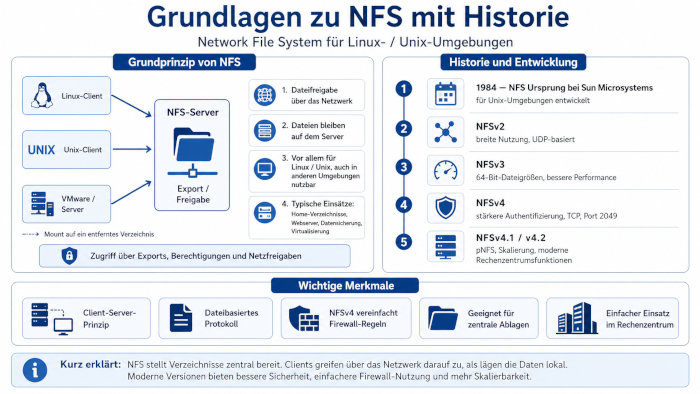
Beim Network File System werden die Dateien nicht, wie zum Beispiel bei FTP, übertragen, sondern bleiben auf dem Server, ein
sogenanntes verteiltes Dateisystem (Distributed File System).
Im Windows-Umfeld entspricht dies SMB bzw. CIFS. Die beiden Protokolle sind aber nicht kompatibel,
nur ähnlich in der Anwendung. Aber auch Microsoft hat in seinen Betriebssystemen NFS implementiert.
Genutzt wird NFS in der gesamten Linux- und Unix-Welt, nicht nur zwischen Clients und zentralen Servern. Auch Server nutzen NFS-Freigaben von anderen Servern, zum Beispiel in
verteilten Webserver-Systemen. Dort liegen an zentraler Stelle die Daten für alle Webserver-Frontends.
NFS wurde mit der Version 1 auf UDP entwickelt, während SMB / CIFS auf TCP basiert. Die Authentifizierung bei den NFS-Versionen bis 3
war rein auf den Client beschränkt. Dies bedeutet, dass der Export auf dem Server auf bestimmte IP-Adressen begrenzt werden kann, nicht aber auf einen Benutzer auf diesem Client. Erst ab
der Version NFSv4 ist eine Benutzer-Authentifizierung möglich.
Aber was ist da der Unterschied? Bei den ersten Versionen von NFS wurden nur IP-Adressen für den Zugriff definiert. Dabei konnte zwischen Read-Only und
Read / Write unterschieden werden, aber nicht auf den Benutzer. Können sich also mehrere Benutzer auf einem NFS-Client anmelden, so dürfen alle Benutzer
den Export auf dem NFS-Server nutzen. Na ja, die Berechtigung auf Dateiebene gibt es trotzdem, das benötigt aber eine einheitliche Anwender-Struktur
auf allen Systemen. Der Benutzer mit der ID 1000 hat Zugriff auf eine Datei auf dem Server, dann muss dieser Benutzer auch die ID 1000 auf dem Client haben. Und auf
anderen Clients, die den gleichen Export nutzen, darf es keine ID 1000 für einen anderen Benutzer geben (der hätte sonst auch Zugriff auf diese Datei).
Das war früher in zentralen Netzen kein Problem, dafür gibt es die zentrale Benutzerverwaltung NIS. Aber in verteilten Unix- und Linux-Umgebungen ist dies nicht mehr möglich und
auch nicht mehr kontrollierbar.
In der Version 4 von NFS werden die Unix-IDs durch einen echten Nutzer in der Form user1@domain1.org ersetzt. Damit ist die Unix-ID durch eine
dezentrale Benutzerkennung ersetzt worden. Die Domain kennzeichnet die Domäne des Servers und die Benutzer-IDs werden auf Unix-IDs auf dem Server gemappt. Damit
ist also keine Beziehung der Unix-IDs zwischen Server und Client notwendig. Das ist das gleiche Prinzip wie bei SMB.
Mit NFSv4 fällt auch UDP weg, bzw. die Port-Problematik gerade für Firewalls. Die Kommunikation läuft über TCP, dafür wird der feste Port 2049 genutzt. Also
nur noch ein Port durch die Firewall freigeben.
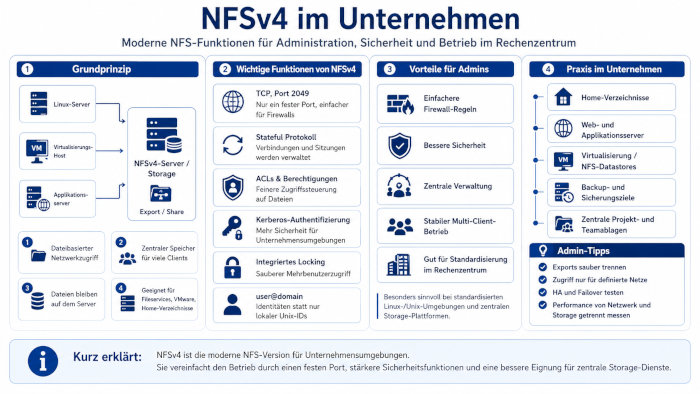
Weiterhin werden auch Cluster-Umgebungen besser unterstützt. Mit der Version 4.1 sind skalierbare parallele Zugriffe über verteilte Server möglich (NFS Multipathing). Mit der Version 4.2 kommen noch Server-Side Clone and Copy dazu, sowie weitere Verbesserungen in pNFS und Space Reservation.
NFS wird zwischen Linux- und Unix-Systemen eingesetzt. Zum Beispiel können hiermit die Benutzer-Verzeichnisse zentral auf einem Server vorgehalten werden.
Meldet sich der Benutzer an einem anderen System an, dann hat er trotzdem alle seine persönlichen Dateien im Zugriff. In der Windows-Umgebung entspricht dies
dem Domänen-Profil eines Benutzers.
Aber nicht nur bei Clients wird NFS eingesetzt, auch im reinen Server-Umfeld ist NFS sehr verbreitet in Linux- und Unix-Systemen. Nehmen wir als Beispiel eine
Webserverfarm. Um den Zugriff der vielen Anwender bewältigen zu können, benötigt man häufig mehrere Webserver, die aber immer den gleichen Inhalt wiedergeben sollen.
Damit man die Dateien nicht auf jedem Webserver vorhalten und entsprechend gleichzeitig überall ändern muss, liegen die Dateien auf einem NFS-Server und alle
Webserver mounten sich dasselbe Dateiverzeichnis. Die Änderung der Dateien erfolgt dann auf dem NFS-Server, also zentral.
Was bei einem Webserver geht, das geht natürlich auch in der Virtualisierung. Auch VMware ESXi hat einen NFS-Client und kann sich Speicher von
einem NFS-Server holen. Das ist sehr einfach, ein Shared Storage ist bei NFS ja schon eingebaut. Aber das Problem ist die Performance. Selbst bei Ethernet mit 10 Gbit/s
ist schnell eine Grenze erreicht.

Aber gerade die Datensicherung ist über NFS wieder sehr einfach möglich. Die Performance ist ja definierbar bzw. steuerbar, dann wird eben nur immer eine virtuelle Maschine zurzeit gesichert. Hierbei ist die einfache Anbindung der große Vorteil. Der NFS-Server und damit das Sicherungsziel kann in einem anderen Brandabschnitt stehen und es wird nur eine Ethernet-Verbindung benötigt.
Was ist NFS und wofür wird es im Rechenzentrum eingesetzt?
NFS (Network File System) ist ein Protokoll, mit dem Server und Clients Dateien über das Netzwerk nutzen können, als lägen sie lokal auf der Festplatte.
Im Rechenzentrum wird NFS häufig für zentrale File-Services, Virtualisierung (zum Beispiel VM-Datastores), Home-Verzeichnisse, Anwendungsdaten und gemeinsame Ablagen genutzt.
Der große Vorteil ist die einfache Bereitstellung: Ein zentraler NFS-Server stellt Speicher bereit, viele Systeme können darauf zugreifen.
Für Entscheider ist wichtig: NFS kann Kosten und Betriebsaufwand senken, wenn man Standards für Performance, Sicherheit und Verfügbarkeit sauber umsetzt.
Was ist der Unterschied zwischen NFS und Block-Storage (zum Beispiel iSCSI/FC)?
NFS ist Datei-Storage: Es liefert Ordner und Dateien. Block-Storage liefert virtuelle Festplatten (Volumes), auf denen der Host selbst ein Dateisystem betreibt.
Datei-Storage ist oft schneller zu verstehen und zu administrieren, weil Berechtigungen und Ordnerstrukturen zentral sichtbar sind.
Block-Storage ist bei manchen Datenbanken oder Spezialanwendungen im Vorteil, weil es dem Host mehr Kontrolle über das Dateisystem gibt.
Praxis-Tipp: Für viele Shared Files-Use-Cases ist NFS ideal, für Low-Latency-Workloads (zum Beispiel Datenbanken) eher Block-Storage.
Welche NFS-Versionen sind im Rechenzentrum relevant (v3, v4.x) und warum?
NFSv3 ist sehr verbreitet und oft einfach und robust, benötigt aber typischerweise zusätzliche Dienste für Locking/Status (je nach Betriebssystem).
NFSv4/v4.1/v4.2 bringt mehr integrierte Funktionen mit, darunter ein moderneres Sicherheits- und Session-Modell und häufig bessere Möglichkeiten für große Umgebungen.
Für Entscheider zählt vor allem: Moderne Arrays und Betriebssysteme setzen in der Regel auf NFSv4.x als Standard,
weil es Features für Skalierung, Sicherheit und Betrieb mitbringt.
Tipp: Legen Sie pro Plattform eine Standardversion fest, statt Mischbetrieb nach Gefühl zuzulassen.
Was ist ein „NFS-Export“ und wie plane ich Exports sinnvoll?
Ein Export ist ein freigegebenes Verzeichnis auf dem NFS-Server, das Clients mounten dürfen.
Sinnvoll ist es, Exports nach Zweck zu trennen: zum Beispiel Archiv-Datastore, Applikationsdaten, Benutzerverzeichnisse, statt einen riesigen /data-Export für alles.
Das erleichtert Berechtigungen, Quotas (Limits), Performance-Tuning und Notfallmaßnahmen.
Praxisbeispiel: Wenn ein Applikationsbereich aus dem Ruder läuft, können Sie nur diesen Export begrenzen oder warten, ohne andere Workloads zu stören.
Wie wird Hochverfügbarkeit (HA) bei NFS erreicht?
HA entsteht entweder durch ein Storage-System mit Controller-Redundanz (typisch bei Enterprise-Arrays)
oder durch Cluster/Failover-Mechanismen bei Fileservern. Wichtig ist, dass Clients Ausfälle ohne manuelle Eingriffe überstehen,
also stabile Failover-Zeiten und saubere Wiederaufnahme von Sessions. In NFSv4.x helfen moderne Session-Konzepte,
und auf Netzwerkseite sind redundante Pfade Pflicht.
Tipp: Testen Sie Failover unter Last (nicht nur im Leerlauf), weil sich dabei die echte Stabilität zeigt.
Wovon hängt die NFS-Performance ab und was sind typische Engpässe?
Die Performance hängt von drei Dingen ab: Netzwerk (Bandbreite, Latenz), Storage-Backend (IOPS/Throughput) und
Client-Konfiguration (Mount-Optionen, Caching, Parallelität). Ein häufiger Engpass ist nicht, dass NFS an sich langsam ist, sondern ein einzelner Flaschenhals wie eine 1G-Anbindung,
überlastete Storage-Controller oder falsch gesetzte MTU/VLAN-Regeln. Bei vielen kleinen Dateien (Metadata-Last) sind andere Optimierungen
relevant als bei großen sequentiellen Dateien (Durchsatz).
Tipp: Messen Sie zuerst, ob das Problem im Netzwerk oder im Storage liegt, das spart Tage an blindem Tuning.
Welche Rolle spielen Mount-Optionen und muss ich da viel tunen?
Mount-Optionen steuern, wie der Client sich verhält (zum Beispiel Zeitüberschreitungen, Retry-Verhalten, Caching).
In vielen Standardfällen liefern Betriebssystem-Defaults solide Ergebnisse, besonders bei NFSv4.x.
Tuning wird relevant, wenn Sie spezielle Anforderungen haben: sehr viele Clients, hohe Metadata-Last, Virtualisierung oder strikte Failover-Ziele.
Praxis-Tipp: Änderungen immer kontrolliert und dokumentiert durchführen, falsche Timeouts oder aggressive Einstellungen können im Fehlerfall mehr schaden als helfen.
Wie sichere ich NFS ab, ohne es unnötig kompliziert zu machen?
Der wichtigste Schritt ist Segmentierung: NFS gehört in ein kontrolliertes Netzwerksegment (VLAN) und sollte nicht einfach so aus jedem Netz erreichbar sein.
Dann kommen klare Export-Regeln: Nur definierte Hosts/Subnetze dürfen mounten, und Rechte werden minimal vergeben (Least Privilege).
NFSv4.x bietet bessere integrierte Sicherheitsmechanismen als ältere Setups, zusätzlich helfen Firewalls und saubere Identitäts-/Berechtigungsmodelle.
Praxis-Tipp: Betrachten Sie NFS wie einen zentralen Datentresor, wer mounten kann, kann oft sehr viel sehen; daher sind Netzwerk- und Zugriffskontrollen entscheidend.


