Storage. Backup. Virtualisierung.
Container-Virtualisierung · Version 1.9 · © Stor IT Back 2026
Container-Virtualisierung ermöglicht es, Anwendungen zusammen mit ihren Abhängigkeiten in isolierten und reproduzierbaren Umgebungen auszuführen. Im Gegensatz zu virtuellen Maschinen besitzen Container keinen eigenen Kernel, sondern verwenden den Kernel des Hostsystems. Dadurch benötigen sie in der Regel weniger Ressourcen und lassen sich schnell bereitstellen, aktualisieren und skalieren.
Docker wird vor allem für anwendungsorientierte Container eingesetzt. LXC stellt dagegen überwiegend systemnahe Linux-Container bereit, die in Bedienung und Aufbau einer leichtgewichtigen virtuellen Maschine ähneln. Kubernetes dient der automatisierten Bereitstellung, Skalierung und Verwaltung containerisierter Anwendungen auf mehreren Servern.
Dieser technische Überblick erklärt den Aufbau von Containern, die Unterschiede zwischen Docker, LXC und virtuellen Maschinen sowie den Einsatz von Kubernetes. Weitere Schwerpunkte sind Container-Images, persistenter Speicher, Sicherheit sowie Backup und Recovery im Unternehmensumfeld.
Zwei wichtige Vertreter der Container-Virtualisierung sind Docker und
LXC (Linux Container). Aber was sind Container eigentlich?
Container nutzen den Kernel des Hostbetriebssystems gemeinsam. Der Container läuft als einzelner Prozess auf dem Host.
Vereinfacht lässt sich ein Container als isolierte Laufzeitumgebung für eine Anwendung betrachten. In einem Container muss also immer eine Applikation
laufen. Ein LXC-Systemcontainer kann sich in Bedienung und Aufbau ähnlich wie ein vollständiges Linux-System verhalten.
Wird diese Applikation oder die Applikationen (es können auch mehrere in einem Container sein) beendet, dann
beendet sich auch der Container. Der Container nutzt Teile des Kernels des Hosts einfach mit, daher ist er ressourcenschonender als eine virtuelle Maschine.
Bei der klassischen Server-Virtualisierung erhält jede virtuelle Maschine virtuelle Hardware,
einen eigenen Kernel und ein eigenes Gastbetriebssystem. Das verbraucht sehr viele Ressourcen, da ja ein zweites komplettes Betriebssystem mit allen
Prozessen und einem eigenen Kernel laufen muss. Weiterhin braucht eine VM deutlich mehr Speicherplatz auf Festplatten, zusätzlich zu Arbeitsspeicher und CPU-Ressourcen.
Eine bildliche Darstellung von Server-Virtualisierung (wie zum Beispiel VMware ESXi oder Microsoft Hyper-V) und Container (Docker oder LXC Linux Container) verdeutlicht die Unterschiede:
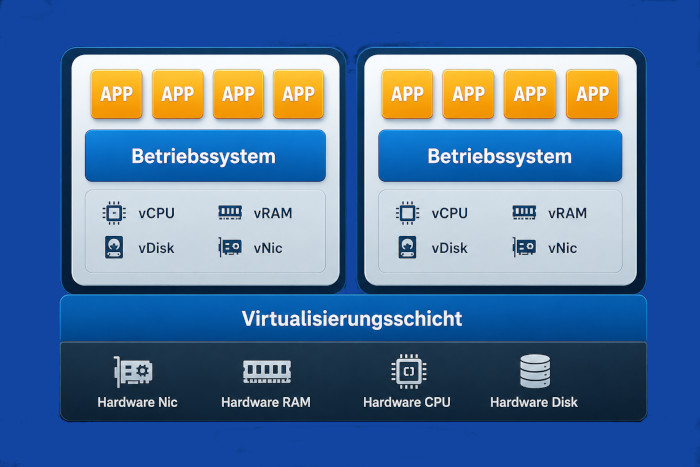

Bei einem Container läuft auf einem Betriebssystem die Docker Engine (Beispiel bei der Docker-Software) und darauf die Container. Der Container hat keine virtuelle Hardware und auch kein eigenes Betriebssystem, bzw. nur einen kleinen Teil des Betriebssystems. Er nutzt Hardware und Kernel vom Hostbetriebssystem mit. Aber was bedeutet dies für die Kompatibilität? Der große Vorteil von Containern soll ja die flexible Nutzung auf unterschiedlichen Systemen sein, ohne umfangreiche Anpassungen. Nehmen wir einmal an, wir hätten einen Container auf einem Linux-System entwickelt, eine Webapplikation auf einem Debian-System. Nun möchten wir diesen Container mithilfe von Docker Desktop auf einem Windows-System ausführen. Dafür wird auf Windows Hyper-V benötigt, also die Server Virtualisierung von Microsoft. Dort wird ein Linux gestartet, ab da wird alles ganz einfach ... Aber ich kann ja auch einen Windows-Container (ein Container, der Windows als Basis hat) erstellen. Die läuft dann in Microsoft Windows Container, die Linux-Container in Docker for Windows.
LXC findet man zum Beispiel in Proxmox VE als
einfach zu bedienende Alternative zu virtuellen Maschinen. Bei Docker ist dies Kubernetes (siehe unten) als Anwendung für die komfortable Nutzung und Bedienung.
Fangen wir erst einmal mit den Gemeinsamkeiten an. Beide nutzen den Kernel des Hosts mit und werden durch Linux-Namespaces und cgroups voneinander und vom
Host getrennt. Sie nutzen eigene Prozesse auf dem Host und stellen eine erweiterte chroot-Umgebung (chroot, eine Funktion um das Root-Verzeichnis zu ändern)
zur Verfügung. Früher nutzten sogar beide Verfahren die LXC-Schnittstelle im Kernel.
Ganz grundsätzlich ähnelt ein LXC-Container eher einer virtuellen Maschine (VM) aus. Auf den ersten Blick kann man kaum Unterschiede erkennen. Es können Applikationen installiert werden und
das mit den gleichen Tools wie auf einer VM. Die fertigen Templates beinhalten das Betriebssystem und die Anwendung. Also zum Beispiel ein Debian 12 mit WordPress. Dort ist
alles enthalten von Datenbank bis Webserver.
Bei Docker (also zum Beispiel im Docker Hub) gibt es auch WordPress, dort besteht (bzw. kann bestehen) das Image aber aus verschiedenen Layern, also zum Beispiel der Datenbank und dem
Webserver. Diese Layer können variieren und dies ist ein großer Vorteil, wenn man sich selbst einen Docker-Container bauen möchte. Man kann also die benötigten Layer kombinieren
und sich dann einen fertigen Container erstellen. Alle diese Layer findet man im Docker Hub zum Download.
Das ist aber auch das größte Problem, man kann schnell die Kontrolle verlieren. Wurde zum Beispiel ein Baustein meines eigenen Containers verändert (zum Beispiel ein Sicherheitsupdate), dann
kann dies die Funktion meiner weiteren Bausteine im Container beeinflussen.
Beim LXC-Container habe ich die volle Kontrolle über alle Komponenten und Bausteine, muss sie aber auch selbst zusammensetzen. Aber auch bei LXC bekomme ich sehr viele fertige
Container, von Nextcloud über ownCloud und Joomla bis WordPress. Und auch Grundsysteme wie Tomcat, LAMP oder einen Samba-Domänencontroller auf Linux. Die einzelnen LXC-Container
sind immer abgeschlossen und können nicht aufeinander aufbauen. Aber sie können jederzeit erweitert werden, also das LAMP zu einem eigenen WordPress, ohne die WordPress-Vorlage
zu nutzen.
Auch das Update eines Containers ist bei Docker und LXC grundsätzlich unterschiedlich. Bei Docker wird der Container quasi komplett neu aus dem Repository heruntergeladen und damit eine neue
Version der Software genutzt. Die eigentlichen Nutzdaten müssen hierbei auf internen Platten des Host-Systems liegen. Liegt zum Beispiel die Konfiguration im Container, dann wird sie beim
Update ersetzt.
Im LXC-Container wird das Update einfach wie bei einer virtuellen oder physischen Maschine durchgeführt. Also bei Debian mit apt update und dann apt upgrade.
Wichtig ist beim LXC, nie zu vergessen,
dass der Kernel des Hosts genutzt wird. Bei Version-Upgrades sollte man also genau schauen, ob der Container später noch läuft, oder der Kernel inkompatibel zum Rest-System wird.
Kubernetes ist eine Open-Source-Plattform für die automatisierte Bereitstellung, Skalierung und Verwaltung containerisierter Anwendungen. Während sich einzelne Docker-Container oder kleinere Anwendungen beispielsweise mit Docker Compose verwalten lassen, unterstützt Kubernetes den Betrieb umfangreicher Container-Umgebungen auf mehreren Servern. Die Plattform überwacht Anwendungen, verteilt Arbeitslasten und kann ausgefallene Container automatisch neu starten oder ersetzen.

Kubernetes ist keine Erweiterung ausschließlich für Docker-Container. Die Plattform kann unterschiedliche Container-Runtimes verwenden,
die über das Container Runtime Interface (CRI) angebunden werden. Häufig kommen beispielsweise containerd oder CRI-O zum Einsatz.
Die Container-Images können trotzdem mit Docker oder anderen OCI-kompatiblen Werkzeugen erstellt und anschließend in einer Container-Registry bereitgestellt werden.
Ein Kubernetes-Cluster besteht grundsätzlich aus einer Control Plane und einem oder mehreren Worker Nodes. Die Control Plane verwaltet den gewünschten Zustand des Clusters und entscheidet beispielsweise, auf welchem Worker Node eine Anwendung ausgeführt wird. Auf den Worker Nodes laufen die eigentlichen Container-Workloads.
Zu den wichtigsten Komponenten der Control Plane gehören:
Auf jedem Worker Node läuft ein Kubelet. Dieser Agent kommuniziert mit der Control Plane und sorgt dafür, dass die für den Node vorgesehenen Pods und Container ausgeführt werden. Zusätzlich stellt eine Container-Runtime die eigentliche Laufzeitumgebung für die Container bereit. Netzwerkkomponenten ermöglichen die Kommunikation zwischen Pods, Services und externen Systemen.
Die kleinste von Kubernetes verwaltete Einheit ist der Pod. Ein Pod enthält einen oder mehrere eng miteinander verbundene Container, die sich unter anderem Netzwerkressourcen und bei Bedarf Speicherbereiche teilen. In den meisten Anwendungsfällen enthält ein Pod einen Hauptcontainer. Z usätzliche Sidecar-Container können beispielsweise Protokolle verarbeiten, Konfigurationen bereitstellen oder Netzwerkfunktionen übernehmen.
Pods werden normalerweise nicht einzeln und dauerhaft von Administratoren angelegt. Stattdessen kommen übergeordnete Kubernetes-Objekte zum Einsatz:
Kubernetes arbeitet nach einem deklarativen Prinzip. Administratoren definieren den gewünschten Zustand einer Anwendung, beispielsweise drei laufende Instanzen eines Webservers. Die Plattform überprüft fortlaufend, ob dieser Zustand tatsächlich vorhanden ist. Fällt ein Pod aus oder reagiert eine Anwendung nicht mehr, kann Kubernetes einen Ersatz-Pod starten.
Diese automatische Wiederherstellung verbessert die Verfügbarkeit, ersetzt jedoch kein Backup. Fehlerhafte Daten, beschädigte Datenbanken oder versehentlich gelöschte Inhalte können von Kubernetes nicht selbstständig wiederhergestellt werden. Persistente Daten und die Konfiguration des Clusters müssen daher in ein eigenständiges Backup- und Recovery-Konzept eingebunden werden.
Anwendungen können in Kubernetes manuell oder automatisiert skaliert werden. Bei einer horizontalen Skalierung wird die Anzahl der Pods erhöht oder reduziert. Ein Horizontal Pod Autoscaler kann dazu beispielsweise die CPU- oder Arbeitsspeicherauslastung sowie anwendungsspezifische Messwerte berücksichtigen.
Die automatische Skalierung von Pods ist von der Bereitstellung zusätzlicher Worker Nodes zu unterscheiden. Reichen die Ressourcen der vorhandenen Nodes nicht mehr aus, wird für eine automatische Erweiterung des Clusters eine zusätzliche Node-Autoscaling-Lösung benötigt. Diese muss mit der verwendeten Cloud- oder Virtualisierungsplattform zusammenarbeiten.
Jeder Pod erhält innerhalb des Clusters normalerweise eine eigene IP-Adresse. Ein Container Network Interface (CNI) stellt die notwendigen Netzwerkfunktionen bereit. Abhängig von der verwendeten Lösung können zusätzlich Netzwerkregeln, Verschlüsselung, Load Balancing und die Anbindung externer Netze umgesetzt werden.
Container und Pods sind grundsätzlich austauschbar und können jederzeit neu erstellt werden. Geschäftsdaten dürfen daher nicht ausschließlich im lokalen, beschreibbaren Dateisystem eines Containers gespeichert werden. Für persistente Daten verwendet Kubernetes unter anderem Persistent Volumes und Persistent Volume Claims.
Storage-Systeme werden in aktuellen Kubernetes-Umgebungen überwiegend über Treiber nach dem Container Storage Interface (CSI) eingebunden. Je nach Hersteller und Plattform können beispielsweise Block-Storage, Dateisysteme, SAN-, NAS- oder Cloud-Speicher verwendet werden. Für produktive Datenbanken und andere zustandsbehaftete Anwendungen müssen Performance, Redundanz, Snapshot-Funktionen und Backup-Möglichkeiten des eingesetzten Storage-Systems berücksichtigt werden.
Kubernetes kann Anwendungseinstellungen über ConfigMaps bereitstellen. Zugangsdaten, Zertifikate und andere vertrauliche Informationen lassen sich als Secrets verwalten. Secrets sollten jedoch nicht als alleiniger Schutz sensibler Daten betrachtet werden. Für produktive Umgebungen sind zusätzlich eine geeignete Verschlüsselung, eingeschränkte Zugriffsrechte und gegebenenfalls eine externe Lösung zur Verwaltung von Zugangsdaten empfehlenswert.
Mit einem Rolling Update kann Kubernetes neue Versionen einer Anwendung schrittweise bereitstellen. Dabei werden alte Pods nach und nach durch Pods mit dem neuen Container-Image ersetzt. Readiness- und Liveness-Prüfungen helfen dabei festzustellen, ob eine Anwendung betriebsbereit ist oder neu gestartet werden muss.
Treten während einer Aktualisierung Fehler auf, kann ein Deployment auf eine vorherige Version zurückgesetzt werden. Ein solches Rollback betrifft jedoch in erster Linie die bereitgestellte Anwendungsversion. Änderungen an Datenbanken oder persistenten Daten müssen gesondert berücksichtigt und gegebenenfalls aus einem Backup wiederhergestellt werden.
Ein produktiver Kubernetes-Cluster benötigt ein umfassendes Sicherheits- und Betriebskonzept. Dazu gehören unter anderem eine rollenbasierte Zugriffskontrolle, abgesicherte Schnittstellen, regelmäßig aktualisierte Container-Images, Netzwerksegmentierung sowie die Überwachung von Cluster-Komponenten und Anwendungen.
Besonders wichtig ist die Begrenzung der Rechte von Containern. Anwendungen sollten möglichst nicht mit Root-Rechten oder privilegiert ausgeführt werden. Zusätzlich sollten nur benötigte Funktionen, Netzwerkverbindungen und Dateisystemzugriffe freigegeben werden. Container-Images müssen regelmäßig auf bekannte Schwachstellen geprüft und aus vertrauenswürdigen Quellen bezogen werden.
Auch Monitoring und Protokollierung gehören zu den grundlegenden Aufgaben. Da Pods dynamisch erstellt und gelöscht werden, dürfen wichtige Protokolldaten nicht ausschließlich innerhalb der Container gespeichert werden. Eine zentrale Logging- und Monitoring-Lösung erleichtert die Fehlersuche, Kapazitätsplanung und Sicherheitsüberwachung.
Kubernetes eignet sich besonders für Unternehmen, die zahlreiche containerisierte Anwendungen auf mehreren Servern betreiben und hierfür eine zentrale, automatisierte Verwaltung benötigen. Typische Anforderungen sind eine hohe Verfügbarkeit, kontrollierte Updates, automatische Skalierung, eine standardisierte Bereitstellung sowie der Betrieb in eigenen Rechenzentren, in der Cloud oder in hybriden Umgebungen.
Für wenige Container auf einem einzelnen Server kann Kubernetes dagegen unnötig komplex sein. In solchen Umgebungen sind Docker Compose, Podman oder vergleichbare Werkzeuge häufig einfacher zu installieren und zu betreiben. Neben den Anwendungen müssen bei Kubernetes auch die Control Plane, das Netzwerk, die Container-Runtime, der Storage und die Sicherheitskomponenten administriert und überwacht werden.
Die Entscheidung für Kubernetes sollte deshalb nicht allein aufgrund der Anzahl der Container getroffen werden. Ausschlaggebend sind vor allem die Anforderungen an Verfügbarkeit, Skalierung, Automatisierung, Standardisierung und den langfristigen Betrieb der Anwendungen.
Container-Technologien verwenden verschiedene Funktionen des
Linux-Kernels, um Prozesse, Dateisysteme, Netzwerke und Ressourcen
voneinander zu trennen.
Docker und LXC basieren auf ähnlichen technischen Grundlagen,
verfolgen jedoch unterschiedliche Ansätze.
Docker wird überwiegend für anwendungsorientierte Container eingesetzt.
LXC stellt dagegen meist systemnahe Linux-Container bereit,
die in Aufbau und Bedienung einer leichtgewichtigen virtuellen Maschine ähneln.
Linux-Namespaces
Namespaces isolieren bestimmte Bereiche des Linux-Systems voneinander.
Container können dadurch unter anderem eigene Prozessnummern,
Netzwerkschnittstellen, Mountpoints, Hostnamen und Benutzerzuordnungen erhalten.
Ein Prozess innerhalb eines Containers sieht damit nur die Ressourcen,
die seinem Namespace zugeordnet wurden.
Control Groups (cgroups)
Control Groups verwalten und begrenzen die Ressourcen,
die einem Container zur Verfügung stehen.
Dazu gehören beispielsweise CPU-Zeit, Arbeitsspeicher,
Festplattenzugriffe und die Anzahl der erlaubten Prozesse.
Außerdem können cgroups Verbrauchswerte erfassen und einzelnen
Containern unterschiedliche Prioritäten zuweisen.
User Namespaces
Ein User Namespace ermöglicht es, Benutzer- und Gruppen-IDs
innerhalb eines Containers anders abzubilden als auf dem Host.
So kann ein Benutzer innerhalb des Containers als
root erscheinen, während er auf dem Hostsystem
lediglich die Rechte eines unprivilegierten Benutzers besitzt.
Diese Trennung ist besonders bei unprivilegierten LXC-Containern
und beim Rootless-Betrieb wichtig.
Linux Capabilities
Linux Capabilities teilen die umfassenden Rechte des
Root-Benutzers in einzelne Berechtigungen auf.
Einem Container können dadurch nur die tatsächlich benötigten
Systemrechte zugewiesen werden.
Nicht benötigte Capabilities sollten entfernt werden,
um die Angriffsfläche zu reduzieren.
seccomp
Mit seccomp lassen sich die Systemaufrufe begrenzen,
die ein Container an den Linux-Kernel übermitteln darf.
Gefährliche oder für die Anwendung nicht benötigte Systemaufrufe
können damit blockiert werden.
AppArmor und SELinux
AppArmor und SELinux sind Linux-Sicherheitsmodule,
mit denen zusätzliche Zugriffsregeln für Prozesse und Container
festgelegt werden können.
Sie ergänzen die Isolation durch Namespaces, cgroups,
Capabilities und seccomp.
LXC – Linux Containers
LXC ist eine Userspace-Schnittstelle zu den Container-Funktionen
des Linux-Kernels.
Die Software stellt Werkzeuge, Programmierschnittstellen und
Konfigurationsmöglichkeiten zum Erstellen und Verwalten
LXC kann sowohl Systemcontainer als auch anwendungsorientierte
Container ausführen.
Plattformen wie Proxmox VE verwenden LXC für den Betrieb
leichtgewichtiger Linux-Systemcontainer.
Systemcontainer
Ein Systemcontainer stellt eine weitgehend vollständige
Linux-Benutzerumgebung bereit.
Darin können mehrere Prozesse, Systemdienste und Anwendungen
gleichzeitig ausgeführt werden.
Ein LXC-Systemcontainer ähnelt daher in Bedienung und Aufbau
einer virtuellen Maschine.
Er besitzt jedoch keinen eigenen Kernel,
sondern verwendet den Kernel des Hosts.
Anwendungscontainer
Ein Anwendungscontainer ist auf eine einzelne Anwendung
oder eine eng zusammengehörende Gruppe von Prozessen ausgerichtet.
Der Lebenszyklus des Containers ist normalerweise an den
Hauptprozess innerhalb des Containers gebunden.
Privilegierter LXC-Container
Bei einem privilegierten LXC-Container entspricht der
Root-Benutzer innerhalb des Containers grundsätzlich dem
Root-Benutzer auf dem Host.
Eine fehlerhafte Konfiguration oder eine Sicherheitslücke
kann dadurch schwerwiegendere Auswirkungen auf das Hostsystem haben.
Privilegierte Container sollten deshalb nur eingesetzt werden,
wenn die Anwendung diese Rechte tatsächlich benötigt.
Unprivilegierter LXC-Container
Bei einem unprivilegierten LXC-Container werden Benutzer- und
Gruppen-IDs über einen User Namespace abgebildet.
Der Root-Benutzer des Containers besitzt dadurch außerhalb
des Containers keine Root-Rechte.
Unprivilegierte Container sind für viele Einsatzgebiete
die bevorzugte und sicherere Betriebsart.
Root-Dateisystem
Das Root-Dateisystem enthält die Linux-Benutzerumgebung
des LXC-Containers.
Dazu gehören Verzeichnisse, Bibliotheken, Programme,
Konfigurationen und installierte Anwendungen.
Der Kernel gehört nicht zu diesem Dateisystem,
da der Container den Kernel des Hostsystems verwendet.
LXC-Template
Ein LXC-Template dient als Vorlage für die Erstellung eines Containers.
Es stellt beispielsweise ein vorbereitetes Root-Dateisystem
für Debian, Ubuntu oder eine andere Linux-Distribution bereit.
Nach der Erstellung lässt sich der Container ähnlich wie
ein gewöhnliches Linux-System konfigurieren und aktualisieren.
Docker Engine
Docker Engine ist die zentrale Plattform zum Erstellen,
Ausführen und Verwalten von Docker-Containern.
Sie umfasst unter anderem den Docker-Daemon,
eine Programmierschnittstelle und die Docker-Kommandozeile.
Docker Engine verwaltet außerdem Images, Container,
Netzwerke und Volumes.
Docker-Daemon
Der Docker-Daemon dockerd läuft als Dienst
auf dem Docker-Host.
Er verarbeitet Anforderungen der Docker-CLI oder anderer Programme
über die Docker-API.
Der Daemon erstellt und verwaltet unter anderem Container,
Images, Netzwerke und Volumes.
Docker CLI
Das Docker Command Line Interface, kurz Docker CLI,
ist das Kommandozeilenwerkzeug zur Bedienung der Docker Engine.
Befehle wie docker run,
docker image,
docker volume oder
docker compose
werden über die CLI an den Docker-Daemon übermittelt.
containerd
containerd verwaltet den Lebenszyklus von Containern.
Dazu gehören unter anderem das Erstellen, Starten,
Stoppen und Überwachen der Container.
Docker Engine verwendet containerd als zentrale Komponente
zwischen dem Docker-Daemon und der eigentlichen Container-Runtime.
runc
runc ist eine schlanke Low-Level-Container-Runtime.
Sie erstellt und startet Container entsprechend der
OCI-Runtime-Spezifikation.
containerd verwendet runc standardmäßig für die eigentliche
Ausführung eines Containers.
Abhängig von den Anforderungen können auch andere
kompatible Runtimes eingesetzt werden.
OCI – Open Container Initiative
Die Open Container Initiative definiert herstellerübergreifende
Standards für Container-Technologien.
Dazu gehören Spezifikationen für das Format von Container-Images,
die Ausführung durch Container-Runtimes und die Verteilung
von Images über Registries.
OCI-kompatible Images und Runtimes erleichtern den Einsatz
unterschiedlicher Werkzeuge und Plattformen.
Container-Image
Ein Container-Image ist eine unveränderbare Vorlage,
aus der Container erstellt werden.
Das Image enthält unter anderem die Anwendung,
benötigte Bibliotheken, Laufzeitkomponenten,
Dateien und grundlegende Startparameter.
Ein Image besteht normalerweise aus mehreren
schreibgeschützten Dateisystemschichten.
Basis-Image
Ein Basis-Image bildet die Grundlage für ein neues Container-Image.
Es kann beispielsweise eine minimale Linux-Benutzerumgebung,
eine Programmiersprache oder eine bestimmte Laufzeitumgebung enthalten.
Im Dockerfile wird das Basis-Image üblicherweise
mit der Anweisung FROM festgelegt.
Image-Layer
Ein Image-Layer ist eine schreibgeschützte Dateisystemschicht
innerhalb eines Container-Images.
Anweisungen wie RUN,
COPY oder ADD
können beim Erstellen des Images neue Dateisystemschichten erzeugen.
Bereits vorhandene Layer lassen sich von mehreren Images
und Containern gemeinsam verwenden.
Container
Ein Container ist eine erstellte oder laufende Instanz
eines Container-Images.
Beim Start erhält der Container zusätzlich zu den
schreibgeschützten Image-Layern eine eigene beschreibbare
Container-Schicht.
Prozesse, Netzwerk, Dateisystem und weitere Ressourcen
werden abhängig von der Konfiguration vom Host
und von anderen Containern isoliert.
Beschreibbare Container-Schicht
Änderungen, die ein laufender Container direkt in seinem
Dateisystem erzeugt, werden in einer beschreibbaren Schicht
oberhalb der Image-Layer gespeichert.
Diese Daten sind an den jeweiligen Container gebunden
und gehen normalerweise verloren, wenn der Container gelöscht wird.
Dauerhaft benötigte Daten sollten deshalb in Volumes,
Bind Mounts oder externem Storage gespeichert werden.
Dockerfile
Ein Dockerfile ist eine Textdatei mit Anweisungen
zum automatisierten Erstellen eines Container-Images.
Es beschreibt beispielsweise das Basis-Image,
zu kopierende Dateien, benötigte Pakete,
Umgebungsvariablen und den beim Start auszuführenden Prozess.
Die meisten Anweisungen werden während des Image-Builds verarbeitet.
CMD und ENTRYPOINT
Die Dockerfile-Anweisungen CMD und
ENTRYPOINT legen fest,
welcher Prozess beim Start eines Containers
standardmäßig ausgeführt wird.
ENTRYPOINT definiert typischerweise
das auszuführende Programm.
CMD kann dazu Standardparameter bereitstellen
oder einen Standardbefehl festlegen.
BuildKit
BuildKit ist das aktuelle Build-Backend von Docker
zum Erstellen von Container-Images.
Es verarbeitet Dockerfiles, optimiert Build-Schritte
und unterstützt unter anderem parallele Abläufe,
Build-Caches, Multi-Stage-Builds und die kontrollierte
Bereitstellung von Secrets während eines Builds.
Multi-Stage-Build
Ein Multi-Stage-Build verwendet innerhalb eines Dockerfiles
mehrere Build-Stufen.
Beispielsweise kann eine Anwendung in einer ersten Stufe
kompiliert und anschließend nur das fertige Ergebnis
in ein kleineres Laufzeit-Image kopiert werden.
Dadurch lassen sich unnötige Entwicklungswerkzeuge
und temporäre Dateien aus dem endgültigen Image entfernen.
Container-Registry
Eine Container-Registry ist ein zentraler Dienst
zum Speichern und Verteilen von Container-Images.
Unternehmen können öffentliche Registries verwenden
oder eine eigene private Registry betreiben.
Images werden mit docker pull
aus einer Registry abgerufen und mit
docker push dorthin übertragen.
Repository
Ein Repository ist ein abgegrenzter Bereich
innerhalb einer Container-Registry.
Es enthält üblicherweise verschiedene Versionen
beziehungsweise Varianten eines Images,
die über Tags oder Digests identifiziert werden.
Docker Hub
Docker Hub ist eine öffentliche Container-Registry von Docker.
Sie enthält öffentliche und private Image-Repositories.
Images aus öffentlichen Repositories sollten vor einem
produktiven Einsatz auf Herkunft, Aktualität,
enthaltene Software und bekannte Sicherheitslücken geprüft werden.
Tag
Ein Tag ist eine lesbare Bezeichnung für eine Variante
oder Version eines Images,
beispielsweise debian:bookworm.
Ein Tag ist grundsätzlich veränderbar und kann später
auf ein anderes Image verweisen.
Der Tag latest bedeutet nicht automatisch,
dass es sich um die sicherste oder fachlich geeignetste
Version handelt.
Digest
Ein Digest ist eine inhaltsbasierte,
kryptografische Kennung eines Images
beziehungsweise Image-Manifests.
Im Gegensatz zu einem veränderbaren Tag kann mit einem Digest
eine konkrete Image-Version eindeutig referenziert werden.
Dies erleichtert reproduzierbare und kontrollierte Bereitstellungen.
Docker Volume
Ein Docker Volume ist ein von Docker verwalteter
Speicherbereich für persistente Daten.
Der Lebenszyklus eines Volumes ist vom Lebenszyklus
eines Containers getrennt.
Ein Container kann daher gelöscht und neu erstellt werden,
ohne dass die im Volume gespeicherten Daten
automatisch verloren gehen.
Volumes eignen sich beispielsweise für Datenbanken,
Anwendungsdaten und andere dauerhaft benötigte Dateien.
Bind Mount
Bei einem Bind Mount wird eine Datei oder ein Verzeichnis
des Docker-Hosts direkt in einen Container eingebunden.
Der Container greift damit unmittelbar auf den
angegebenen Hostpfad zu.
Bind Mounts sind flexibel, erzeugen jedoch eine stärkere
Abhängigkeit von der Verzeichnisstruktur und der
Konfiguration des Hostsystems.
tmpfs Mount
Ein tmpfs Mount speichert Daten ausschließlich
im Arbeitsspeicher des Hostsystems.
Die Daten werden nicht dauerhaft auf einen Datenträger geschrieben
und gehen beim Entfernen des Containers oder beim Neustart
des Hosts verloren.
tmpfs eignet sich beispielsweise für kurzlebige
oder besonders sensible temporäre Daten.
Externer Storage
Container können persistenten Speicher auch über externe
Storage-Systeme erhalten.
Abhängig von der Umgebung kommen beispielsweise NFS,
Block-Storage, verteilte Dateisysteme oder Storage-Treiber
eines Herstellers zum Einsatz.
Für produktive Anwendungen müssen Performance,
Verfügbarkeit, Zugriffsrechte, Snapshots sowie
Backup und Recovery berücksichtigt werden.
Docker Network
Docker-Netzwerke ermöglichen die Kommunikation
zwischen Containern sowie die Anbindung an externe Netze.
Abhängig vom eingesetzten Netzwerktreiber können Container
isolierte interne Netze, Hostnetzwerke oder
standortübergreifende Netzwerke verwenden.
Port-Mapping
Mit einem Port-Mapping wird ein Port des Docker-Hosts
einem Port innerhalb des Containers zugeordnet.
Dadurch lässt sich ein im Container laufender Dienst
über die IP-Adresse des Hosts erreichen.
Freigegebene Ports sollten auf die tatsächlich benötigten
Schnittstellen und Quellnetze beschränkt werden.
Docker Compose
Docker Compose beschreibt und verwaltet Anwendungen,
die aus einem oder mehreren Containern bestehen.
In einer Datei wie compose.yaml
werden unter anderem Services, Images, Netzwerke,
Volumes, Umgebungsvariablen, Abhängigkeiten
und Portfreigaben definiert.
Die gesamte Anwendung kann anschließend beispielsweise
mit docker compose up gestartet und mit
docker compose down beendet werden.
Service
Ein Service beschreibt innerhalb einer Compose-Anwendung
eine bestimmte Aufgabe oder Anwendungskomponente.
Typische Services sind beispielsweise ein Webserver,
eine Datenbank und ein Reverse Proxy.
Diese Komponenten werden normalerweise in getrennten
Containern ausgeführt und über Docker-Netzwerke
miteinander verbunden.
Environment Variables
Umgebungsvariablen können einer Anwendung beim Start
des Containers Konfigurationswerte übergeben.
Passwörter, private Schlüssel und andere vertrauliche
Informationen sollten jedoch nicht ungeschützt
in Dockerfiles, Images oder öffentlich zugänglichen
Compose-Dateien gespeichert werden.
Secrets
Secrets sind vertrauliche Informationen wie Passwörter,
Zertifikate, Schlüssel oder Zugriffstoken.
Sie sollten getrennt vom Container-Image verwaltet
und nur den Anwendungen zur Verfügung gestellt werden,
die diese Daten tatsächlich benötigen.
In größeren Umgebungen kann dafür eine externe
Secrets-Management-Lösung sinnvoll sein.
Healthcheck
Ein Healthcheck prüft regelmäßig, ob eine Anwendung innerhalb eines Containers funktionsfähig ist.
Die größte Akzeptanz finden Container bei Softwareentwicklern, die verschiedene Versionen ihrer Software auf unterschiedlichen Systemen entwickeln und
testen müssen. Was sind dort die konkreten Vorteile der Container? Die Entwickler können auf einem Basissystem (dem Docker-Host) verschiedene Versionen von
Betriebssystemen mit verschiedenen Versionen ihrer Software kombinieren und dann testen. Da die Container aus einzelnen Layern aufgebaut sind, lassen sie sich einfach
und schnell kombinieren und starten.
Aber nicht nur bei der Software-Entwicklung spielen Container eine immer größere Rolle, auch bei Administratoren in Unternehmen. In Containern können einfach und
schnell Anwendungen den Nutzern zur Verfügung gestellt werden, für die eigentlich keine Betriebssysteme vorhanden sind oder Voraussetzungen nicht erfüllt sind. Aber auch
ein Update der Anwendung wird deutlich einfacher. Der Container wird ja aus einem Image gestartet und das kann für verschiedene Nutzer immer das gleiche sein (siehe das Beispiel
mit dem Webserver oben). Das Update muss also nur auf dem einen versionierten Container-Image durchgeführt werden und nach einem Neustart der Container haben alle Anwender die neue Version. Sie stellen
einen Fehler in der neuen Applikation fest, aber haben es schon an alle Nutzer verteilt? Kein Problem, das alte Image wiederherstellen und alle Container neu starten. Mit
einer klassischen Softwareverteilung ist das nicht möglich, bzw. mit deutlich mehr Aufwand.
Bei der Datensicherung einer Docker-Umgebung müssen mehrere Komponenten getrennt betrachtet werden. Dazu gehören die Container-Images, die Konfiguration der Umgebung, persistente Anwendungsdaten, Datenbanken, Secrets sowie gegebenenfalls die Einstellungen des Docker-Hosts. Ein einzelner Befehl kann daher normalerweise kein vollständiges und anwendungskonsistentes Backup der gesamten Umgebung erstellen.
Container-Images sollten möglichst reproduzierbar aus einem versionierten Dockerfile erstellt und in einer geschützten Container-Registry gespeichert werden. Die Konfiguration der Anwendungen kann beispielsweise in Docker-Compose-Dateien, Umgebungsdateien und einer Versionsverwaltung dokumentiert werden. Zugangsdaten und andere Secrets dürfen dabei nicht ungeschützt in Images oder öffentlich zugänglichen Repositories gespeichert werden.
Der Befehl docker commit kann Änderungen im beschreibbaren Dateisystem eines Containers als neues Image speichern.
Er ist jedoch kein vollständiges Backup-Verfahren. Daten aus eingebundenen Docker Volumes oder Bind Mounts werden nicht in das neue Image übernommen.
Produktive Daten sollten nicht ausschließlich in der beschreibbaren Schicht eines Containers liegen. Für persistente Daten eignen sich Docker Volumes, Bind Mounts oder externe Storage-Systeme. Diese Speicherbereiche müssen mit einem dafür geeigneten Backup-Verfahren gesichert werden.
Bei Datenbanken genügt es häufig nicht, lediglich die zugehörigen Dateien zu kopieren. Für eine konsistente Sicherung sollten die von der Datenbank bereitgestellten Backup- oder Exportfunktionen verwendet werden. Alternativ kann eine anwendungskonsistente Snapshot- oder Backup-Lösung eingesetzt werden.
Für die Wiederherstellung werden zunächst der Docker-Host beziehungsweise eine geeignete Container-Plattform und die benötigten Netzwerke und Speicherbereiche bereitgestellt. Danach lassen sich die Images aus der Registry abrufen und die Container anhand der dokumentierten Docker-Compose- oder Orchestrierungskonfiguration neu erstellen. Abschließend werden die persistenten Daten zurückgesichert und die Anwendung auf Konsistenz und Funktionsfähigkeit geprüft.
Ein vollständiges Backup-Konzept sollte daher mindestens folgende Bestandteile umfassen:
Die Sicherung sollte auf ein vom Produktivsystem getrenntes Backup-Ziel übertragen und in das unternehmensweite Backup- und Notfallkonzept eingebunden werden. Eine zusätzliche unveränderbare oder offline gelagerte Kopie schützt die Container-Daten vor Manipulation und Ransomware.
Container sind isolierte Laufzeitumgebungen, in denen Anwendungen zusammen mit ihren benötigten Bibliotheken und Abhängigkeiten ausgeführt werden. Im Gegensatz zu virtuellen Maschinen besitzen Linux-Container keinen eigenen Kernel, sondern verwenden den Kernel des Hostsystems. Dadurch benötigen sie häufig weniger Ressourcen und lassen sich schnell starten, aktualisieren und vervielfältigen. Container eignen sich unter anderem für Webanwendungen, Microservices, Testumgebungen und automatisierte Bereitstellungsprozesse.
Eine virtuelle Maschine erhält virtuelle Hardware und führt ein vollständiges Gastbetriebssystem mit eigenem Kernel aus. Container verwenden dagegen den Kernel des Hostsystems gemeinsam und isolieren hauptsächlich Prozesse, Dateisysteme, Netzwerke und Ressourcen. Deshalb benötigen Container häufig weniger Speicherplatz und Arbeitsspeicher und starten schneller. Virtuelle Maschinen bieten jedoch eine stärkere Trennung und ermöglichen den parallelen Betrieb unterschiedlicher Betriebssysteme und Kernel.
Ein Container-Image ist eine unveränderbare Vorlage, aus der ein oder mehrere Container gestartet werden. Es enthält die Anwendung, benötigte Bibliotheken, Laufzeitkomponenten und grundlegende Konfigurationen. Bei Docker wird der Aufbau eines Images üblicherweise in einem Dockerfile beschrieben. Daraus wird ein versionierbares Image erstellt, das in einer Container-Registry gespeichert und auf unterschiedlichen Systemen reproduzierbar bereitgestellt werden kann.
Kleinere Container-Umgebungen lassen sich beispielsweise mit Docker Compose verwalten. Für umfangreiche und hochverfügbare Umgebungen kommen Orchestrierungsplattformen wie Kubernetes zum Einsatz. Sie verteilen Anwendungen auf mehrere Server, überwachen den Zustand der Container und unterstützen Skalierung, Service Discovery, kontrollierte Updates und den automatischen Neustart ausgefallener Workloads. Die Einführung einer Orchestrierungsplattform erhöht jedoch auch die Anforderungen an Administration, Monitoring, Netzwerk und Storage.
Container sind voneinander isoliert, verwenden jedoch denselben Kernel des Hostsystems. Sicherheitsrisiken entstehen unter anderem durch veraltete Images, zu weitreichende Berechtigungen, unsichere Konfigurationen und ungeschützt gespeicherte Zugangsdaten. Container sollten möglichst ohne Root-Rechte und nicht privilegiert ausgeführt werden. Zusätzlich sind minimale Basis-Images, regelmäßige Sicherheitsupdates, Image-Scans, eingeschränkte Netzwerkzugriffe und eine sichere Verwaltung von Secrets erforderlich.
Container benötigen zuverlässige Hostsysteme, stabile Netzwerke und eine geeignete Speicherumgebung. Der tatsächliche Bedarf an CPU, Arbeitsspeicher, Storage und Netzwerkleistung hängt von den ausgeführten Anwendungen ab. Für produktive Cluster sind zusätzlich redundante Management-Komponenten, Load Balancing, Monitoring, zentrale Protokollierung und ein geeignetes Backup-Konzept erforderlich. Zustandsbehaftete Anwendungen benötigen außerdem persistenten Storage, der unabhängig vom Lebenszyklus eines Containers verfügbar bleibt.
Container eignen sich besonders für Webanwendungen, APIs, Microservices, CI/CD-Pipelines, automatisierte Tests und zeitlich begrenzte Hintergrundprozesse. Anwendungen lassen sich damit standardisiert und reproduzierbar in Entwicklungs-, Test- und Produktionsumgebungen bereitstellen. Unternehmen können Container außerdem für hybride Architekturen und den Betrieb in eigenen Rechenzentren oder in der Cloud einsetzen. Voraussetzung ist, dass die Anwendung für einen containerisierten Betrieb geeignet ist.
Nicht jede Anwendung lässt sich ohne Anpassungen in einem Container betreiben. Schwierigkeiten können bei Anwendungen entstehen, die spezielle Hardwarezugriffe, grafische Benutzeroberflächen, umfangreiche Systemdienste oder enge Abhängigkeiten vom Betriebssystem benötigen. Auch persistenter Storage, Netzwerkkommunikation, Monitoring und Backup müssen gezielt geplant werden. Bei größeren Umgebungen steigt zudem die Komplexität durch Orchestrierung, Sicherheitsrichtlinien und die Verwaltung zahlreicher Images und Abhängigkeiten.