
Überwachung und Monitoring von Storage- und Backup-Lösungen V1.9 (c) Stor IT Back 2025
Eine Storage-Lösung ist implementiert, es laufen einige Proxmox VE, VMware ESX oder
Hyper-V Server mit einer großen Anzahl von virtuellen Maschinen, die natürlich
auch gesichert werden. Aber wer überwacht die gesamte Umgebung?
Muss man das überhaupt monitoren oder ist alles so sicher, dass es
ohne menschliche Kontrolle läuft? Schließlich nutzt man ja Cluster Lösungen mit automatischer Umschaltung!
Auch hochredundante Storage-Systeme müssen überwacht werden.
Wer merkt es sonst, dass eine Festplatte ausgefallen ist? Das Storage-System
merkt es und verschickt evtl. sogar eine Mail an den Administrator. Wenn dieser
aber im Urlaub ist und die Vertretung dieses Postfach nicht überwacht? Alles
kein Problem: Die Hot Spare springt ja ein! Aber ist sie wirklich eingesprungen?
Was passiert beim nächsten Ausfall? Es ist ja keine Hot Spare mehr da.
Alles Fragen über Fragen.
Was auch häufig vergessen wird, das sind die Tape-Libraries. In den meisten großen Unternehmen sind sie im Einsatz,
Bänder werden erstellt, sie werden kopiert und ausgelagert, aber die Hardware wird selten überwacht. Aber
auch dort kann ein Tape-Laufwerk ausfallen, oder ein redundantes Netzteil.
Nicht nur Ausfälle können überwacht werden, sondern auch "schleichende Fehler". Was kann das sein? Ein Beispiel sind Netzwerkports,
diese können durch leichte Probleme den Durchsatz ändern, also von 10 Gbit/s auf 1 Gbit/s abfallen. Die Verbindung bleibt erhalten,
aber die Performance könnte extrem gestört sein. Damit sehen dann Anwender in ganz anderen Bereichen plötzlich Beeinträchtigungen, eine
umfangreiche Suche nach der Ursache startet. Mit einem Monitoring-System hätte man das Problem sofort erkannt.
Ein anderes Beispiel sind Server oder VMs, die immer mehr RAM verbrauchen. Wird dies nicht überwacht, kann es auch dort nach eine gewissen Laufzeit zu
Performance-Problemen kommen.
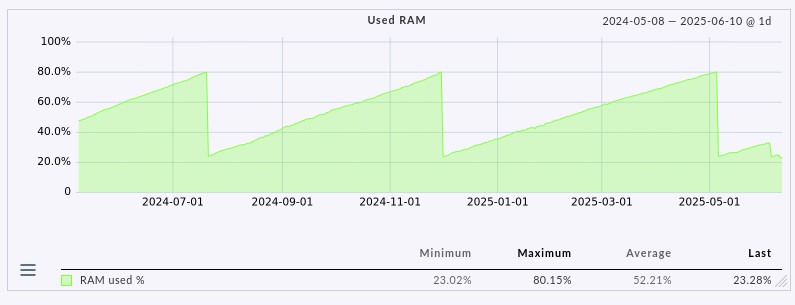
Wir sehen in dem Screenshot, das bei dem überwachten System der RAM-Verbrauch über Monate langsam ansteigt und bei ca. 80% kommt
es zu ersten Auswirkungen, das System wir neu gestartet und der Verbrauch geht wieder auf 20% zurück. In diesem Bild ist der
Fehler sehr einfach zu sehen, ohne Monitoring aber schwer zu analysieren.
Also muss eine zentrale Monitoringstelle her. Ein Server, der alle anderen
Systeme und auch das Netzwerk überwachen kann und ständig den Status meldet. Wenn etwas
schief läuft, so sollte das System eine Mail verschicken können, oder
eine SMS oder einen Anruf ausführen. Diese Alarmierungspfade sollten natürlich
nicht alle von den gleichen Komponenten abhängen sein bzw. es sollten so
wenig Abhängigkeiten wie möglich vorhanden sein.
Ein einfaches Beispiel:
Der E-Mail Server fällt aus und wird auch überwacht. Die Überwachung
bemerkt den Fehler und verschickt eine E-Mail an den Administrator. Das klappt
jetzt aber nicht wegen dem fehlenden Mail-Server. Für diesen Fall muss
ein zweiter Weg vorhanden sein. Entweder eine direkte Alarmierung oder zusätzlich
eine SMS über einen anderen Weg.
Und natürlich muss das Monitoring auch überwacht werden. Wenn
eine Überwachung "problemlos" läuft, dann verlässt
man sich sehr schnell zu 100% darauf. Fällt jetzt aber dieser zentrale
Monitoringserver aus, so kann er auch nicht mehr alarmieren. Also sieht
alles so aus, als ob keine Probleme da sind, obwohl sich die Server so "langsam
alle auflösen". Einfach Lösung für diesen Fall: Ein zweiter
Überwachungsserver, der den ersten überwacht. Hört sich seltsam
an, ist aber sinnvoll und auch einfach zu realisieren. Und der sollte natürlich nicht auf der Virtualisierungs-Lösung oder dem Storage laufen, oder
von diesen abhängig sein
Für diesen Zweck gibt es viele Programme, komplette Umgebungen, aber auch
einfache kleine Überwachungssysteme. Basierend auf Windows Betriebssystemen
oder Linux, oder als eigene Appliance. Prinzipiell sollte die Überwachung auf einem zuverlässigen
System laufen und auf einem Betriebssystem, mit dem man sich gut auskennt. Wenn
zum Beispiel die Überwachung auf einer virtuellen Umgebung läuft und
auch diese soll überwacht werden, dann wird der Ausfall des physikalischen
Servers sicherlich nicht mehr bemerkt werden, außer die Überwachung
wird auch wieder überwacht (siehe oben). Eine häufig angewendete Lösung ist
die zentrale Überwachung als virtuelle Maschine auszuführen und einen
kleinen Server (auf einer Hardware, die zum Beispiel bei der Virtualisierung
überflüssig geworden ist) als Überwachung für die "virtuelle
Überwachung" aufzubauen. Mehr kann man dann schon nicht mehr machen,
für die meisten Unternehmen ist dies sicherlich ausreichend.
Wir stellen hier als Beispiel die Checkmk Software vor, die in der RAW Version auf Nagios basiert. Checkmk ist in der Raw Edition quasi ein Frontend für Nagios, die
Enterprise Version nutzt dann ein eigenes Backend mit besserer Effizienz.
Warum gerade Checkmk?
1. Checkmk ist kostenfrei (die RAW Version) und läuft unter Linux, daher fallen keine zusätzlichen
Lizenzkosten an.
2. Es gibt aber auch kostenpflichtige Versionen (Checkmk Enterprise und Cloud) mit Support vom Hersteller Checkmk GmbH, für alle größeren Umgebungen.
3. Checkmk (und die Basis Nagios) ist weit verbreitet, bei Problemen findet man im Internet schnell
und kostenfrei Hilfe.
4. Für Checkmk (und die Basis Nagios) gibt es unzählige Plugins (sehr viele kostenfreie) um alle möglichen und
unmöglichen Geräte zu überwachen.
5. Checkmk lässt sich sehr einfach durch eigene Skripte oder Programme erweitern.
6. Checkmk läuft sogar auf einem Mini PC, also auch für kleine Umgebungen gut geeignet oder für die Überwachung des eigentlichen Monitorings.
Was benötigt man für den Betrieb von Nagios?
1. Einen Server (egal ob virtuell oder physikalisch) mit Linux als Betriebssystem (Ubuntu, Debian).
2. Know How in der Bedienung eines Systems über die Command Line.
3. Know How im Betrieb eines Linux Systems.
4. Etwas Zeit und Mühe zur Einarbeitung.
Für die Installation von Checkmk gibt es zahlreiche Anleitungen im
Internet. Ein guter Startpunkt für Checkmk ist die offizielle Seite von Checkmk.
Dort gibt es die Software zum Download, Anleitungen und Foren. Alles was man
braucht, um die Software zum Laufen zu bekommen. Unsere Anleitungen basieren
immer auf einem lauffähigen Checkmk-Server mit allen für Checkmk benötigten
Erweiterungen. Wird spezielle Software für ein Plugin benötigt, so
weisen wir darauf hin.
Wir haben als Beispiel unser Checkmk auf einem Debian 12 installiert und dies als virtuelle Maschine. Ein kurzes Video zum Vorgehen finden Sie hier:

Die Installation von Checkmk auf Debian 12 in einer VM
Download: Offizielle Seite von Checkmk, und dort dann über die Editionen auf RAW.
Den aktuellen Download-Link bzw. das Vorgehen finden Sie dann nach Auswahl des Betriebssystems.
a) gpg installieren: apt install gpg
b) dann den Schlüssel herunterladen: wget https://download.checkmk.com/checkmk/Check_MK-pubkey.gpg
c) Schlüssel installieren: gpg --import Check_MK-pubkey.gpg
d) und dann das Paket prüfen mit: gpg --verify ./check-mk-raw-2.4.0p3_0.bookworm_amd64.deb
e) Installation der Software: apt install ./check-mk-raw-2.4.0p3_0.bookworm_amd64.deb
f) Test der Installation mit omd version
g) Anlegen der Instanz: omd create schulung
h) Starten der Instanz: omd start schulung
i) CLI Anmeldung an der Instanz: omd su schulung
Hinweis: Es wird der root User verwendet, ansonsten muss ein sudo vorangestellt werden.
Ist Checkmk erst einmal auf einem Server installiert, dann ist das nur die halbe Miete. Jetzt sollte das System als erstes einmal abgesichert werden. Das betrifft den Zugriff auf die Webseite, die ist noch unverschlüsselt, und den Zugriff auf den Agent. Der Agent überträgt auch unverschlüsselt und antwortet zur Zeit noch jedem. Das sollte also schnellstens behoben werden.
Wichtige Aufgaben: Die Website von Checkmk mit HTTPS und den Agent absichern.
Auch hier die wichtigen Befehle für Copy & Paste:
Apache Module prüfen: apachectl -M | grep -E 'headers|rewrite|ssl'
Apache Module aktivieren: a2enmod ssl
SSL Site aktivieren: a2ensite default-ssl.conf
Apache neu starten: systemctl restart apache2
Agent absichern: cmk-agent-ctl register --hostname agent-server --server checkmk-server --site sitename --user agent_registration --password copypaste
Checkmk kann die Alarmmeldungen per E-Mail verschicken, aber das muss erst einmal konfiguriert werden. Checkmk braucht hierfür einen MTA auf dem Checkmk Server und der muss installiert und konfiguriert werden. Beispiele für einen MTA (Mail Transfer Agent) sind exim4 und postfix. Wir nehmen in diesem Video exim4.
Wichtige Aufgaben: E-Mails von Checkmk verschicken.
Wichtigen Befehle aus dem Video für Copy & Paste:
Exim4 installieren unter Debian: apt update und apt install exim4
Konfigurations-Datei von exim4 (Debian spezifisch): /etc/exim4/update-exim4.conf.conf
Konfiguration aktivieren: update-exim4.conf
MTA neu starten: systemctl restart exim4.service
Checkmk überwacht einen Proxmox VE Server direkt mit dem Linux Agent. Die Installation erfolgt wie unter jedem anderen Debian System. Die Standard-Monitoring-Werte sind bei dem PVE vorhanden, sie können aber durch eigene Skript erweitert werden. So können spezielle Zustände von VMs überwacht werden, wie zum Beispiel die Anzahl der Sicherung oder Snapshots.

Überwachung von Proxmox VE Server über den Linux Agent
Das Vorgehen für die Installation des Agents ist identisch mit einem normalen Linux Agent:
1. Den passenden Link in der Weboberfläche bei Setup, Agents und Linux kopieren
2. Auf dem PVE in der CLI mit wget das File herunterladen
3. Das File mit apt install ./Filename installieren
4. Absichern des Agents mit cmk-agent-ctl register ... (siehe oben)
Zusätzlich sollte die API genutzt werden.
Hinweis: Nur die neusten Checkmk Versionen bieten zusätzlich Daten für die VMs (z.B. der Backup-Status) durch die API.
Checkmk überwacht einen Windows Server direkt mit dem Windows Agent. Die Installation erfolgt wie bei Windows üblich über ein Installations-File, welches auf dem Windows Server gestartet wird. Dort wird ein Dienst installiert und auch gestartet, sowie die Firewall entsprechend geöffnet. Die Standard-Monitoring-Werte sind bei dem Windows Agent vorhanden, sie können aber durch eigene Skript erweitert werden. So können Anwendungen auf dem Windows Server direkt überwacht werden, wie zum Beispiel die Veeam Sicherungen auf dem Veeam Server. Hierfür gibt es schon offizielle Erweiterungen auf dem Checkmk Server.
Überwachung von Windows Servern über den Windows Agent
Das Vorgehen für die Installation des Agents:
1. Den passenden Link in der Weboberfläche bei Setup, Agents und Windows kopieren
2. Auf dem Windows Server mit einem Browser das File herunterladen
3. Dann das File installieren
4. Absichern des Agents mit cmk-agent-ctl.exe register --hostname win-name --server cmk-ip --site Site-Name -- user agent_registration --password Password
Checkmk kann direkt Geräte über SNMP überwachen. Hierzu muss nur das Gerät im Checkmk-Server angelegt und mit den entsprechenden Sicherheitsvorgaben eingestellt werden. Checkmk nutzt hierzu die Versionen von v1, v2c und v3. Der Unterschied zwischen den Versionen ist ein unterschiedlicher Sicherheitslevel und verschiedene Abfrage-Geschwindigkeiten. Die Version v1 ist veraltet und wird nur noch bei älteren Geräten genutzt. In der Praxis wird die v2c eingesetzt, wobei das c für Community steht, das Passwort bei SNMP. Die Version 3 kommt zum Einsatz, wenn der Datenverkehr verschlüsselt sein soll. Dies benötigt auf beiden Seiten deutlich mehr Rechenleistung.
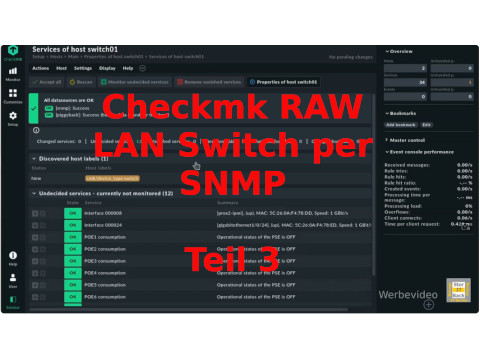
Überwachung von LAN Switches und anderen Devices per SNMP
Wichtig ist hierbei, dass Checkmk die Geräte immer aktiv abfragt. Damit ist sichergestellt, das eine Meldung nicht verloren geht. SNMP Traps werden
von Checkmk nicht verarbeitet, wenigstens nicht direkt.
SNMP hört sich auf den ersten Blick recht einfach an, ist aber im Detail recht komplex, so liefert zum Beispiel Checkmk über 1000 SNMP Plugins
für unterschiedliche Geräte aus und dies ist noch lange nicht vollständig. Daher benötgit man von Gerät zu Gerät eventuell etwas
mehr Experimente.
Dell EMC Unity Systeme lassen sich mit Checkmk einfach und sicher überwachen.
Allerdings ist die Überwachung nicht mit SNMP möglich und Agent kann auf der Unity auch nicht installiert werden. Es gibt aber
in den Erweiterungspaketen von Checkmk (MKP) von Usern entwickelte Skripte, die ein Monitoring ermöglichen.
Diese sind über "Checkmk Exchange" erreichbar, unter https://exchange.checkmk.com/.
Hier kann nach Erweiterungen gesucht werden. Für unser Besipeil suchen wir einfach nach "Unity" und bekommen einige Ergebnisse. Diese
sollte man genau filtern und untersuchen. Einige Erweiterungen sind schon sehr alt, einige nur eingeschränkt nutzbar, viele aber wenigstens ein guter
Einstieg. Wir haben in diesem Fall ein Plugin gewählt (https://exchange.checkmk.com/p/emcunity-4), es ist
aktuell, hat auch einige Versionen (wird also weiter entwickelt). Das alles sollte einen aber nicht davon abhalten, die Programme genau zu untersuchen und zu testen.
Eine Garantie auf eine einwandfreie und zuverlässige Funktion gibt es nicht.
Für die Unity wird dann noch ein API Programm von Dell EMC benötigt. Dies ermittelt die Informationen aus dem Storage System und die Auswertung übernimmt dann das Skript.
Dies gibt es für Dell EMC Kunden auf den Support-Seiten des Herstellers.
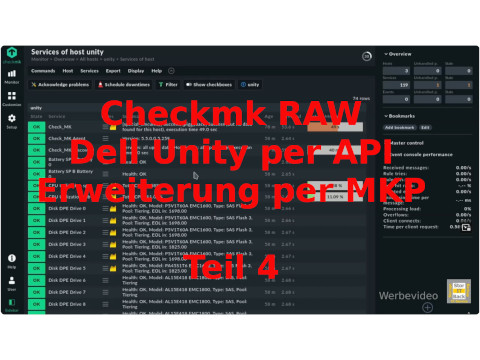
Überwachung eines Dell EMC Unity Storage per API
Weitere Informationen aus dem Video für Copy&Paste:
omd su schulung mkp add /tmp/emcunity-4.1.0.mkp mkp enable emcunity mkp list exit apt update apt install alien alien -d UnisphereCLI-Linux-64-x86-en_US-5.5.0.2450450-1.x86_64.rpm apt install ./unispherecli-linux-64-x86-en-us_5.5.0.2450450-2_amd64.deb ln -s /opt/dellemc/uemcli/bin/uemcli.sh /usr/bin/uemcli
Achtung:
Gerade die Lösung mit dem Link auf das Skript ist Quick and Dirty und sollte für produktive Umgebungen so nicht
angewendet werden. Besser ist es das MKP-Skript auf den richtigen Pfad anzupassen und dort auch den Library-Pfad zu
ergänzen.
Zur Grundkonfiguration gibt es auch viele Seiten im Internet. Eine lauffähige
Konfiguration sollte man schon nach der Installation haben. Es sollte mindestens
der Nagios Server selbst überwacht sein. Die Webseite zur Anzeige sollte
fehlerfrei laufen und E-Mail (oder SMS) sollten im Fehlerfalle den Empfänger
erreichen.
Wichtig bei Nagios: Die Konfiguration erfolgt über Dateien, in denen sämtliche Objekte und
Überwachungen definiert werden. Einerseits sehr schnell zu bedienen, wenn einfach nur weitere
Überwachungen kopiert werden müssen. Aber bei neuen Funktionen mit verschiedenen Abhängigkeiten
eventuell mit viel Fehlersuche verbunden.
Auch VMware ESXi Server lassen sich über Nagios überwachen, aber natürlich auch andere Virtualisierungen. Fertige Plugins basieren auf verschiedenen Möglichkeiten der Überwachung eines ESXi-Server. Entweder die Auswertung der Webseite des ESX oder über das Command-Line-Tools von VMware. Damit lassen sich alle Informationen aus einem ESX oder ESXi Server herauslesen. Bei passender Hardwareunterstützung auch der komplette Hardware-Status der Maschine, sowie der Zustand von Festplatten und RAID-Verbünden.
Unser Beispiel basiert auf einem Python Skript, welches die Webseite des ESX über https abfragt und auswertet. Da dieses Skript sehr kurz und übersichtlich ist, lassen sich dort auch spezielle Funktionen abfragen, wie zum Beispiel der Status des RAID.
1. Python installiert und konfiguriert auf dem Nagios Server
2. "Python WBEM Client and Provider Interface": pywbem-1.4.1 (oder
neuer, bzw. dem Plugin angepasst, https://pywbem.github.io/)
3. Download des Plugin:
https://exchange.nagios.org/directory/plugins/operating-systems/-2a-virtual-environments/vmware/check_esxi_hardware-2epy/details/
Aufruf des Plugin: ./check_esx_wbem.py hostname user password [verbose]
Sehr wichtig ist hierbei der Parameter "verbose". Er bewirkt, dass dieses Skript alle Informationen, egal ob gut oder schlecht ausgibt. Damit lassen sich Fehler schnell finden und es gibt einen Überblick, wie dieses Skript an die eigenen Bedürfnisse angepasst werden kann. Hier mal eine gekürzte Ausgabe des Skriptes im verbose-Modus:
20110326 17:26:28 Element Name = System Board 1 1.8V PG 0 20110326 17:26:28 Element Op Status = 2 20110326 17:26:28 Element Name = System Board 1 1.25V PG 0 20110326 17:26:28 Element Op Status = 2 20110326 17:26:28 Element Name = System Board 1 PROC VTT 0 20110326 17:26:28 Element Op Status = 2 20110326 17:26:28 Element Name = Processor 1 VCORE 0
Durch kleine Änderungen im Skript können aber auch Ergebnisse angezeigt werden. Sollen zum Beispiel Festplatten, RAID-Controller und RAID-Sets überwacht und aufgelistet werden, so kann dies leicht erreicht werden. Die Ausgabe des Skriptes ist dann:
Element Name = Drive 0 on controller 0 Fw: SN06 - ONLINE Element Name = Drive 1 on controller 0 Fw: SN06 - ONLINE Element Name = Drive 2 on controller 0 Fw: SN06 - ONLINE Element Name = Drive 3 on controller 0 Fw: SN06 - ONLINE Element Name = Controller 0 (SAS6IR) Element Name = RAID 1 Logical Volume 2 on controller 0, Drives(2,3) - OPTIMAL Element Name = RAID 1 Logical Volume 0 on controller 0, Drives(0,1) - OPTIMAL
Also eine einfache und sichere Überwachung auch von kostenlosen ESXi Varianten, auch wenn eine größere Anzahl davon betrieben wird.
Brocade Fibre Channel Switche lassen über SNMP sehr einfach überwachen. Brocade stellt hierfür eine eigene MIB zur Verfügung, die dieses Plugin auch benötigt. Es gibt in diesem Bereich verschiedene Plugins. In diesem Beispiel beschränken wir uns auf die Überwachung der Hardware. Denkbar sind auch Überwachungen von Durchsatzmengen mit Alarmierungen ab einem bestimmten Auslastungsgrad.
1. SNMP für Nagios, zur Fehlersuche auch snmpwalk (oder ähnliche
Tools)
2. SNMP MIB von Brocade für den FC Switch
3. Nagios Plugin für Brocade FC Switche:
http://exchange.nagios.org/directory/Plugins/Hardware/Network-Gear/Brocade/Monitor-FC-Brocade-Switch/details
4. Freigabe des Nagios Server für SNMP Abfragen auf dem Brocade Switch
Dieses Plugin ist ein Shell Skript. Es kann also direkt auf der Command Line aufgerufen werden. Wie üblich werden die IP-Adresse mit -H und die Community mit -c angegeben.
nagios:~# ./check_FCBrocade_hardware.sh -H 10.0.0.128 -c public HARDWARE OK : SLOT#0TEMP#1=29C, SLOT#0TEMP#2=27C, SLOT#0TEMP#3=28C, SLOT#0TEMP#4=28C, FAN#1=5273RPM, FAN#2=5443RPM, FAN#3=5443RPM, FAN#4=5443RPM, PowerSupply#1=1, PowerSupply#2=1,|29;27;28;28;5273;5443;5443;5443;1;1;
Hinweis: Die Zahlen in dem "|" sind die Performance-Daten aus der Auswertung, also die Temperaturen und Umdrehungen.
Sollte ein Netzteil ausgefallen sein, so ändert sich die Auswertung auf die folgende Ausgabe:
nagios:~# ./check_FCBrocade_hardware.sh -H 10.0.0.128 -c public HARDWARE CRITICAL : SLOT#0TEMP#1=29C, SLOT#0TEMP#2=27C, SLOT#0TEMP#3=28C, SLOT#0TEMP#4=28C, FAN#1=5273RPM, FAN#2=5443RPM, FAN#3=5443RPM, FAN#4=5532RPM, PowerSupply#1=0, status=faulty|29;27;28;28;5273;5443;5443;5532;0;1;
Damit bekommt Nagios dann auch den Return-Code vom Skript für die Fehlermeldung.
Die Infortrend Raid-Systeme lassen sich über SNMP überwachen. Auch hierfür gibt es bereits fertige Plugins aus der Nagios-Gemeinde. Das Basis-Skript haben wir von: Infortrend Nagios Plugin.
1. SNMP für Nagios, zur Fehlersuche auch snmpwalk (oder ähnliche
Tools)
2. Nagios Plugin: Infortrend Nagios Plugin
3. Test des Infortrend Gerätes mit snmpwalk auf die richtigen SNMP Einstellungen
Es sind insgesamt 3 Skripte, einmal zur Überwachung der Hardware, dann zur Überwachung der Festplatten und als drittes die Überwachung der Logical Drives.
Skript zur Überwachung der Hardware:
nagios:~/Infortrend-1.2# ./check_ift_dev.pl -H 10.1.1.71 -c public WARNING: PSUs: OK SLOT1: Inactive, Empty
In diesem Beispiel ist ein Netzteil ausgeschaltet bzw. nicht eingesteckt.
Skript zur Überwachung der Festplatten:
nagios:~/Infortrend-1.2# ./check_ift_hdd.pl -H 10.1.1.71 -c public CRITICAL: Drive 1: Drive Absend () Drive 3: Drive Absend () Drive 4: Drive Absend () Drive 5: Drive Absend () Drive 6: Drive Absend () Drive 7: Drive Absend () Drive 8: Drive Absend () Drive 9: Drive Absend () Drive 10: Drive Absend () Drive 11: Drive Absend () Drive 12: Drive Absend ()
In diesem Beispiel ist nur eine Festplatte vorhanden, alle anderen werden als "nicht vorhanden" gekennzeichnet.
Skript zur Überwachung der Logical Drives (RAID Sets):
nagios:~# ./check_ift_ld.pl -H 10.1.1.71 -c public OK: LD1: (Good) Online-HDD=1 HotSpare=0 HDDs=1 Failed=0 NON-RAID
In diesem Fall ist ein Logical Drive vorhanden, es hat eine Festplatte, ist
damit von dem Typ "NON-RAID" und hat keine Hot Spare Platte.
Ist kein Logical Drive angelegt (z.B. weil das Gerät gerade neu ist), dann
kommt eine etwas "seltsame" Fehlermeldung:
nagios:~# ./check_ift_ld.pl -H 10.1.1.71 -c public CRITICAL: The requested table is empty or does not exist for 0


