Stor IT Back - Ihr Speicherspezialist
Cluster - Einführung V1.6 (c) Stor IT Back 2023
Ein Cluster soll die Verfügbarkeit und/oder Skalierbarkeit einer Anwendung erhöhen. Daraus lassen sich zwei Arten von Clustern ableiten, die zwar ähnlich aufgebaut sind, jedoch auch wichtige Unterschiede besitzen. Dies ist einmal der reine Hochverfügbarkeits-Cluster (HA), der nur die Verfügbarkeit einer Anwendung erhöhen soll. Die zweite Art erhöht auch die Verfügbarkeit, aber zusätzlich wird die Skalierbarkeit verbessert. Dies hört sich nach starken Vorteilen des zweiten Clustertyps an, jedoch ist er nicht für jede Anwendung geeignet.
Dieser Cluster erhöht die Verfügbarkeit der Anwendung durch eine konsequente Vermeidung eines Single-Point-of-Failure im Gesamtsystem. Dies wird auf der Hardware-Seite durch eine Verdoppelung der Komponenten erreicht. Sollte ein Server oder ein Storage-System ausfallen, dann übernimmt der Partner die Arbeit. Konsequenter Weise sollten auch alle Komponenten innerhalb von Server und Storage-System redundant ausgelegt werden. So wird durch diese einfachen und kostengünstigen Maßnahmen die Grundverfügbarkeit jedes Einzelsystems deutlich erhöht.

Eine Anwendung kann in diesem Fall nur auf einem der beiden Rechner laufen.
Fällt dieser Rechner aus, so übernimmt der andere sämtliche Funktionen, das
heißt die IP-Adresse, die Daten und die Anwendung. Ist nur eine Anwendung
vorhanden, so läuft der jeweils andere Rechner ohne eigentliche Funktion (= Anwendung für die User) vor
sich hin. In diesem Falle kann der Cluster unsymmetrisch aufgebaut werden, der
normale Produktionsrechner als großer und leistungsfähiger Server, die Ersatzmaschine
als Minimalsystem. Eine mögliche Aufgabe für das "Ersatzsystem" ist die Testumgebung.
Diese kann im Fehlerfalle deaktiviert werden und das Produktionssystem darf
die volle Rechnerkapazität nutzen.
Die Auslegung des Storage-Systems bzw. der Storage-Systeme ist für diesen
Cluster recht einfach. Es muss nur möglich sein, dass zwei Rechner gleichzeitig
auf den Storage zugreifen können, es muss also mindestens zwei Host-Eingänge
besitzen. Dies ist schon mit "einfachen" SAS-RAID-Systemen möglich.
Für das Betriebssystem des Servers muss ein Software-RAID-1 verfügbar
sein, welches durch den Cluster unterstützt wird. Oder die beiden Storage-Systeme replizieren ihre Daten untereinander, so dass beide Storages immer
exakt die gleichen Daten haben.
Ist dies nicht möglich,
so kann nur mit einem Storage-System gearbeitet werden. In diesem Fall muss
eine Storage-Hardware den Verfügbarkeitsanforderungen genügen. Eine
Ergänzung kann dann auch die zusätzliche Replikation der Daten sein.
Sollte eine Anwendung
auf einem einzelnen Server nicht mehr die geforderten Antwortzeiten erreichen, so kann
erst einmal der Server aufgerüstet werden. Dies kommt schnell an Grenzen. Effektiver
ist es da schon, wenn die gleiche Anwendung mit den gleichen Daten auch noch
auf einem zweiten Rechner zur gleichen Zeit laufen könnte.
Und dies ermöglicht der Lastausgleichs-Cluster. Die Anwendung wird auf dem zweiten Server gestartet
und greift auch auf die gleichen Daten zu. Aber dort liegt auch das Problem.
Die Anwendung muss den Zugriff von mehreren Rechnern auf seine Datenbasis erlauben.
Dies funktioniert sehr gut bei Webservern, bei Datenbanken kommen Probleme auf (da gibt es aber Lösungen, z.B. Oracle RAC),
die meistens auf anderen Wegen gelöst werden müssen. Soll zusätzlich die Verfügbarkeit
gesteigert werden, so muss auf die Auslegung des Lasterverteilers und des NAS
Storage besonderen Wert gelegt werden. Hier sollten dann HA-Cluster eingesetzt
werden.

Wird der NAS Storage durch ein Fibre Channel Storage ersetzt, so müssen spezielle Filesysteme eingesetzt werden (SAN Filesysteme oder Cluster Filesysteme), die einen schreibenden Zugriff von verschiedenen Rechnern auf ein Filesystem ermöglichen. Mit dieser Konfiguration können auch Datenbanken auf diesem Cluster betrieben werden. Die Hauptanwendung ist aber meist die Webanwendung oder Videostreaming. Immer wenn hohe Datenraten benötigt werden, wird auf ein SAN- bzw. Fibre Channel-Storage zurückgegriffen.
Gerade die Server Virtualisierung benötigt eine hohe Verfügbarkeit, ansonsten fallen ja alle virtuellen
Maschinen aus, die auf dieser Hardware laufen. Dort wird fast in jeder
Umgebung ein Cluster eingerichtet, egal ob mit VMware vSphere, Hyper-V oder KVM/Proxmox. Der Cluster ist
bei diesen Lösungen der Standard und nicht etwas Besonderes.
Auch die Einrichtung ist extrem einfach. Als Beispiel
bei VMware muss man nur mindestens 2 ESXi Server dem vCenter Server hinzufügen und dann für den definierten
Cluster die Konfiguration starten. Dort werden einige Parameter zur Überwachung und zum Neustart von virtuellen Maschinen
hinterlegt und die eigentliche Konfiguration übernimmt der vCenter dann auf den ESXi. Die eigentliche Funktion im
Cluster von VMware ist HA. Diese Funktion überwacht ganz nach dem Motto eines Clusters die physikalischen Maschinen (ESXi) und die
virtuellen Maschinen (zum Beispiel über den internen Heartbeat, Management-LAN). Bei einer Störung werden die virtuellen Maschinen neu gestartet oder
auf eine andere physikalische Maschine umgezogen.
Sollte also zum Beispiel ein ESXi im Verbund mit einem oder zwei anderen ausfallen, so werden nach einer kurzen Zeit (die anderen ESXi müssen den
Ausfall ja erst einmal feststellen), die virtuellen Maschinen neu auf den beiden anderen ESXi gestartet. Also einen kurzen Ausfall muss man in diesem
Fall hinnehmen, aber ein manueller Eingriff ist nicht notwendig.
Hinweis: Sollte schon ein kurzer Ausfall zu lang sein, dann bietet VMware die Funktion "Fault Tolerance" an. Dort laufen die virtuellen Maschinen
auf zwei getrennten ESXi, so dass beim Ausfall die andere VM (ist ja die gleiche) sofort antworten kann.
Benötigt wird im Fall eines Clusters für die Server-Virtualisierung das Shared Storages. Dieses ist in jedem Fall notwendig, damit jeder Server auf
die gemeinsamen Daten zugreifen kann. Neben einem Shared Storage ist auch das VSAN von VMware oder die OpenSource Lösung Ceph möglich. Diese Produkte erstellen
ein verteiltes Storage.
Eine typische Anwendung für einen HA-Cluster ist ein NAS-Server. Liegen die wichtigen Firmendaten auf dem NAS-System und sind längere Ausfallzeiten nicht akzeptabel, so muss das NAS-System hochverfügbar ausgelegt werden. Es entsteht ein typischer HA-Cluster, es sind mehrere NAS-Köpfe (Server) vorhanden, die auf gespiegelte Daten zugreifen. Ein weiterer Ausbau der Verfügbarkeit liegt in der räumlichen Trennung der Systeme in unterschiedliche Brandabschnitte oder Gebäude. Solche Verfahren bieten sogar Schutz gegen Brand und Wasserschaden. Abstände von 500 Metern lassen sich ohne Probleme und sehr kostengünstig mit Fibre-Channel-Systemen erreichen. Auch bei Performanceproblemen gibt es eine Lösung im NAS-Bereich. Mehrere NAS-Server greifen auf die gleiche Datenbasis zu. Hierfür wird jedoch eine spezielle Software benötigt, die den konkurrierenden Schreibzugriff ermöglicht. In diesem Bereich bieten wir individuelle Lösungen an, setzen Sie sich mit uns in Verbindung.
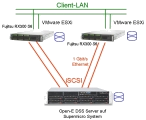
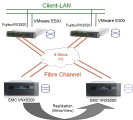
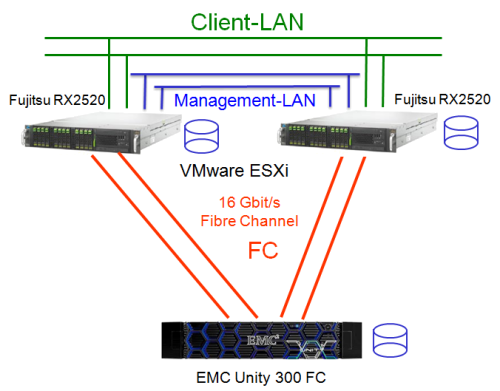
Für viele Anwendungen wird ein hochverfügbarer Storage benötigt. Meist müssen die beiden Knoten auch in unterschiedlichen Brandabschnitten oder Gebäuden untergebracht werden. Die Server werden dann mit beiden Storage-Systemen (= den beiden Knoten) verbunden und können sowohl auf die Daten über den Knoten 1, wie auch über den Knoten 2 zugreifen. Sollte dann ein Knoten ausfallen, dann können alle Server weiterhin auf die Daten zugreifen.

Diese Storage-Cluster gibt es in zwei Varianten. Die gebräuchlichste ist
der Active-Passive-Cluster, dies bedeutet einer der beiden Knoten ist aktiv
und als einziger stellt er Speicherplatz für die Server zur Verfügung.
Der aktive Knoten repliziert dann alle Änderungen auf den passiven Knoten.
Sollte der aktive Knoten ausfallen, so über nimmt der passive Knoten alle
Aufgaben. Ist der defekte Knoten wieder aktiv, so repliziert der laufende Knoten
alle Änderungen wieder zurück und der ehemals defekte Knoten kann
wieder der aktive Knoten werden. Die zweite Variante der Active-Active Cluster
ist wesentlich aufwendiger. Beide Knoten sind aktiv und beide Knoten stellen
Speicherplatz zur Verfügung. Eine Anfrage der Server kann an beide Knoten
gehen, das bedeutet die Storage Cluster Knoten müssen sich bei jedem I/O
abstimmen. Aber beide Knoten können I/Os beantworten, die Performance ist
größer als bei Active-Passive-Cluster.
Im obigen Beispiel sind als Backend zwei Storage Systeme vorhanden, die ihre
Daten replizieren und im Fehlerfalle einen Failover bieten. Damit können
die beiden Server im Beispiel auch bei Ausfall eines Storage-Systems weiter
auf die Daten zugreifen. Die beiden Server sind auch wieder ein Cluster, in
diesem Beispiel ein VMware vSphere Cluster. Der Storage-Cluster erhöht
nur die Verfügbarkeit, die Performance kann so nicht erhöht werden
(Active-Passiv), da immer nur ein System aktiv ist. Der Server-Cluster, also
die VMware-Umgebung ist sowohl ein HA-Cluster, wie auch ein Cluster zur Steigerung
der Performance, da beide Server zu gleichen Zeit aktiv sein können.
VMware hat für diesen Fall ein Cluster-Filesystem auf den ESXi-Servern
laufen, das sogenannte VMFS Filesystem. Dank diesem Filesystem können mehrere
Server zur gleichen Zeit schreibend auf eine Datenbasis zugreifen. Dies ermöglicht
dann auch die Features wie vMotion und VMware HA.